Understanding MTTR in cybersecurity: A complete guide



MTTR in cybersecurity is a performance metric that measures how quickly a security team deals with incidents. It reflects the time it takes to move from detecting an incident to resolving it and helps teams evaluate the effectiveness of their incident response processes.
This guide fully explains MTTR in a cybersecurity context, including how it’s measured, why it matters for incident response and recovery, how it relates to other key metrics, and what organizations can do to reduce response and recovery times.
What is MTTR in cybersecurity?
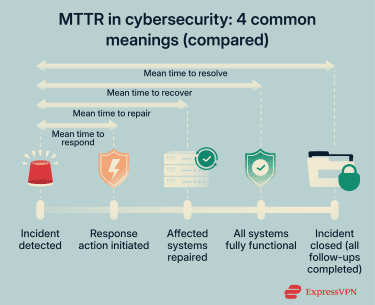
Unlike many straightforward metrics, MTTR doesn’t have a single, universally accepted definition. Depending on the framework or organization, it’s commonly used in four related ways:
- Mean time to repair: Measures the time from when an incident is first detected until the affected systems are fully repaired.
- Mean time to respond: Measures how quickly a team takes action after an incident is detected.
- Mean time to recovery: Measures the time from incident detection to the restoration of full business operations.
- Mean time to resolve/resolution: Encompasses the entire incident lifecycle from detection through complete resolution, including all investigation, remediation, and documentation activities.
How to calculate MTTR
The basic formula to calculate MTTR applies to all variants:
MTTR = Total time spent on incidents ÷ number of incidents
For example, if a team spends a combined 400 hours resolving 20 security incidents, the MTTR is 20 hours.
There isn’t a single acceptable MTTR that applies to every organization. A reasonable target depends on factors like:
- Incident severity: Restoring a locked user account takes less time than rebuilding compromised infrastructure.
- System criticality: Customer-facing services, identity systems, and payment flows usually require faster repair targets than internal tools.
- Environment complexity: Cloud-native systems, legacy dependencies, and third-party vendors can all affect repair time.
- Recovery design: Organizations with tested backups, failover, and automation can usually repair faster than those relying on manual steps.
A practical way to judge whether your MTTR is acceptable is to compare it against:
- Your own historical baseline: Is MTTR trending downward quarter over quarter for similar incident types?
- Your incident response lifecycle timing: Where is the most time being spent in the response lifecycle, such as investigation or approvals, and does that indicate a process bottleneck that could be improved?
- User impact: How long were users affected, and did repair time align with business continuity expectations?
Accurate MTTR calculation also requires defining what counts as time spent.
- For mean time to repair, you measure from initial detection to complete restoration of the affected system.
- For mean time to respond, you measure from detection to initial response action.
- For mean time to recovery, you track from detection until full business operations resume.
- For mean time to resolve, you track from detection to the closure of the incident ticket.
Additionally, it’s important to calculate MTTR for specific timeframes, such as monthly or quarterly, to help you identify trends. A single month's MTTR might be skewed by one major incident, but quarterly averages can help reveal genuine patterns in your security operations.
Common mistakes in MTTR calculation
MTTR becomes less meaningful and harder to interpret when calculated incorrectly. Inaccurate numbers can give teams a false sense of how effective their incident response really is, making it harder to spot gaps, prioritize improvements, or compare performance over time.
Some of the most common issues include:
- Mixing definitions: Combining response time, repair time, and recovery time into a single number without clarification.
- Including unrelated delays: Counting downtime caused by external factors, such as vendor dependencies, without context.
- Averaging vastly different incidents: Treating minor alerts and complex breaches as equivalent can distort results.
- Ignoring outliers: Extremely long or short incidents can skew MTTR if they aren’t reviewed separately.
- Evaluating MTTR in isolation: Measuring MTTR alone can be misleading, as it ignores factors such as incident complexity and severity. When paired with detection, acknowledgment, frequency, and impact metrics, it gives a more accurate view of incident response performance.
- Starting the clock at the wrong time: MTTR can be skewed depending on when the measurement begins. Some teams start timing when an alert fires, while others start when an analyst begins active investigation. Defining a consistent start point helps ensure MTTR reflects real response effort rather than tooling gaps.
To avoid these pitfalls, MTTR should be paired with clear documentation and, where possible, segmented by incident type or severity. This makes the metric easier to interpret and more useful for improving incident response processes.
How MTTR relates to other cybersecurity metrics
MTTR is usually useful when it’s viewed alongside other incident response metrics. On its own, it shows how long incidents take to handle. Combined with related measurements, it can help explain why response and recovery take the time they do and where teams can improve.
MTTR vs. MTBF
Mean time between failures (MTBF) focuses on reliability. It measures the average time between incidents or system failures, or the frequency of security issues.
Neither metric alone tells the whole story. A high MTBF and MTTR could mean you're preventing most attacks but are unprepared for those that succeed.
A low MTBF and MTTR suggest you're constantly firefighting. Your response is efficient, but you might be addressing symptoms rather than root causes. The ideal security program should optimize both metrics.
MTTR vs. MTTD and MTTA
MTTR is closely tied to earlier stages of the incident response lifecycle, which are measured by mean time to detect (MTTD) and mean time to acknowledge (MTTA).
- MTTD: Measures how long it takes on average to identify that an incident has occurred. The clock starts when an attacker first compromises a system or when malicious activity begins and stops when your security tools or team discover the threat.
- MTTA: Tracks the average time it takes for a team to recognize, triage, and assign the incident once detected. Your security information and event management (SIEM) system might detect an anomaly instantly, but if that alert sits in a queue for hours before an analyst reviews it, your MTTA reveals this delay.
| Metric | Measures | Clock starts | Clock stops |
| MTTD (mean time to detect) | How long it takes (on average) to identify that an incident occurred. | When an attacker first compromises a system or malicious activity begins. | When the threat is discovered by security tools or the security team. |
| MTTA (mean time to acknowledge) | How long it takes to recognize, triage, and assign an incident after detection. | When the incident is detected or an alert is generated. | When a human acknowledges it (triaged and assigned). |
| MTTR (mean time to respond / remediate / recover)* | How long it takes to respond to, fix, and resolve an incident after detection. | When the incident is detected. | When the defined endpoint is reached (for example: response complete, repair done, service restored, or incident fully resolved). |
* MTTR should always be defined on first use.
These metrics represent a sequence. Slow detection (MTTD) or delayed acknowledgment (MTTA) can increase MTTR by allowing incidents to progress further before containment begins.
Tracking these metrics together helps teams pinpoint where delays actually occur. If MTTD is high, investment in monitoring and alerting may be needed. If MTTA is the bottleneck, triage workflows or on-call processes may need to be refined.
MTTR in modern cyber threat scenarios
Modern cyber threats vary widely in scope, complexity, and impact. Because of this, MTTR can look very different depending on the type of incident and how it unfolds. Understanding how MTTR behaves across common threat scenarios helps teams set realistic expectations.
MTTR in ransomware incidents
Responses to ransomware typically start with detection, followed by containment, isolation, and then recovery. If these phases aren’t clearly coordinated, MTTR can increase as teams move back and forth between tasks or delay recovery.
In these cases, MTTR is influenced by factors such as:
- How quickly ransomware is detected.
- Whether containment steps are automated or manual.
- The availability and integrity of backups.
- The time required to verify that systems are clean and safe to restore.
For well-prepared organizations with tested response plans and backups, recovery typically takes one to three days.
The relationship between MTTD and MTTR is especially pronounced in ransomware scenarios. Detecting ransomware early may allow remediation within hours, while detection during active encryption may require extended recovery and investigation that can take days (or longer).
In ransomware scenarios, shorter MTTR is usually easier to achieve when teams have strong preparation, including clear playbooks, tested backups, and predefined escalation paths that outline who to notify and when.
MTTR challenges in zero-day exploits
Zero-day exploits present a different challenge because they involve vulnerabilities that aren’t yet publicly documented or patched. Detection can take longer, and response decisions often need to be made with incomplete information.
MTTR often increases in zero-day scenarios due to:
- Indirect detection signals.
- Limited guidance on effective mitigation steps.
- The need for temporary controls or compensating measures.
- Coordination with vendors or internal development teams.
- The trade-offs between applying new patches immediately to prevent exploitation and risking breaking production systems if the patch itself has issues.
In these situations, MTTR reflects not only technical response speed but also decision-making processes. Teams that have flexible response frameworks and clear authority models are often better positioned to act quickly without waiting for full remediation guidance.
MTTR in man-in-the-middle (MITM) and rogue Wi-Fi incidents
Man-in-the-middle (MITM) attacks and rogue Wi-Fi incidents are network security threats that can dramatically increase MTTR. Their deceptive nature and broad potential impact usually make them challenging to detect and resolve quickly.
Determining what data was intercepted, which users were affected, and what modifications occurred typically requires extensive analysis.
MTTR in MITM and rogue Wi-Fi incidents is usually impacted by:
- Detection speed: Since MITM attacks and rogue access points often resemble normal traffic, delays are likely to occur when teams rely on manual reviews or user reports.
- Network visibility: Limited visibility increases investigation time and slows response. Wireless intrusion detection and prevention systems can help lower MTTR by detecting and providing information about rogue devices.
- Containment capabilities: The faster compromised connections can be terminated or access revoked, the shorter the overall response time.
- User awareness and reporting: Sometimes, MTTR depends on how quickly users recognize warning signs, such as certificate errors or unexpected login prompts, and report them. Delayed reporting allows the incident to continue longer than necessary.
Why faster containment matters in modern attacks
Modern attacks move fast. Attackers rarely stop at the first system they compromise. They use that initial foothold to move deeper into the network, escalate privileges, and expand their impact. This is why MTTR matters so much in real-world scenarios: the longer an incident remains active, the more damage attackers can cause.
Fast containment reduces the blast radius of an attack. If security teams can quickly isolate affected endpoints, disable compromised accounts, or block malicious traffic, they keep the breach small and prevent a single compromise from turning into a company-wide event.
Quick containment and a lower MTTR can directly reduce impact by:
- Preventing lateral movement: Many attackers aim to jump from one machine to another until they reach sensitive systems. Fast containment can cut off that path early.
- Reducing the risk of data theft: Shorter exposure time limits how long attackers can access files, email inboxes, databases, or cloud apps, which directly protects user and customer privacy.
- Stopping ransomware escalation: Ransomware actors often spend time exploring the environment, disabling backups, and identifying high-value targets before encrypting systems. The faster the response, the harder it becomes for them to complete this chain.
- Minimizing downtime and operational disruption: Containing incidents early usually means fewer systems are affected, making recovery faster and less expensive.
In short, high MTTR gives attackers time to operate, while low MTTR increases the chance that the incident is contained before it turns into a full-scale breach.
How network security impacts MTTR
Network security controls affect your organization's MTTR by influencing how quickly incidents are detected, contained, and resolved. Networks with strong visibility give security teams clear insight into traffic, devices, and user activity through logging, monitoring, and alerts, while networks that utilize segmentation separate devices, servers, and critical systems into different network zones.
Together, these measures make it easier to spot issues early, isolate affected systems, and reduce the scope of investigations. Poorly secured networks tend to increase MTTR by making incidents harder to trace and contain.
How encrypted connections reduce attack opportunities
Encrypted network traffic helps limit the opportunities attackers have to intercept or manipulate data in transit. By protecting communications between devices, services, and users, encryption reduces the likelihood of certain attack paths that can complicate incident response.
In business settings, this protection typically comes from enterprise VPNs. They help protect corporate communications even when employees use unsecured networks.
By reducing the likelihood of credential interception in transit, enterprise VPNs can lower both incident frequency and the scope of investigations when security events do occur.
From an MTTR perspective, encrypted connections can:
- Reduce the number of compromised sessions that need investigation.
- Limit lateral movement across the network.
- Simplify scoping by narrowing where exposure may have occurred.
While encryption doesn’t prevent all attacks, it can reduce incident complexity, which in turn helps shorten investigation and resolution timelines.
Lowering MTTR through reduced network intrusions
Networks that minimize unnecessary exposure tend to experience fewer and more contained security incidents. Practical controls, such as properly configured firewalls, strict access rules, and regular patching, help block unauthorized traffic before it reaches internal systems.
Network segmentation further reduces risk by limiting which systems can communicate, so a single compromised device is less likely to lead to a wider intrusion.
Continuous monitoring also plays a key role. Tools that track network traffic and system activity can surface suspicious behavior early, allowing teams to intervene before minor issues escalate.
When intrusions are limited in scope:
- Fewer systems require forensic review.
- Containment actions can be applied more precisely.
- Recovery efforts are easier to validate.
This supports lower MTTR by reducing the amount of work required to return systems to a stable state.
Supporting faster response for remote and hybrid teams
Remote and hybrid work environments add complexity to incident response because users connect from varied networks and locations. Without consistent network protections, incidents can take longer to detect and scope.
Standardized security controls across remote connections can help reduce these delays. Examples include always-on enterprise VPNs, centralized identity access management (IAM) with multi-factor authentication (MFA) and conditional access, endpoint detection and response (EDR) on all devices, and centralized logging to a SIEM. These controls improve visibility into off-network activity, enable faster containment regardless of user location, and reduce delays caused by inconsistent access paths.
Quick operational wins that can reduce MTTR
Small operational improvements can significantly shorten response and recovery time, even without major changes to security infrastructure.
Common examples include:
- Dedicated incident communication channels: Using a single, predefined channel in internal messaging tools helps centralize updates and speed up coordination during an incident.
- Pre-populated incident templates: Standardized templates for incident tracking, handoffs, and reporting reduce decision overhead and ensure critical information is captured early.
- Snapshot-based recovery: Regular system snapshots and tested restore procedures can dramatically shorten recovery time by allowing teams to revert affected systems quickly and safely.
- Basic response automation: Automating repetitive tasks such as alert enrichment, ticket creation, or evidence collection helps analysts focus on investigation and containment.
These measures don’t eliminate the need for the deeper detection and response capabilities we discuss below, but they can reduce friction during high-pressure incidents and help teams respond more consistently.
How organizations improve MTTR
Reducing MTTR also requires improving incident detection, prioritization, and resolution throughout the response lifecycle. Here are some practical strategies:
Automation and orchestration
Automation helps security teams handle routine tasks faster and more consistently. When common response actions are automated, analysts spend less time on manual steps and more time on decision-making.
For example, when a potential malware infection is detected, a manual response might involve an analyst logging into multiple systems to gather host information, checking antivirus logs, reviewing network traffic, querying threat intelligence feeds, and documenting findings in a ticketing system. This process could take a significant amount of time. Automated workflows complete the same tasks instantly.
Automation and orchestration can reduce MTTR by:
- Automatically triggering containment actions: Predefined rules and response playbooks can initiate actions such as isolating a device or blocking a network connection when specific indicators are detected, reducing delays caused by manual handoffs.
- Enriching alerts with relevant context: Automated workflows can pull in supporting information, such as affected assets, user details, or known threat indicators, so analysts don’t need to gather this data manually before making decisions.
- Standardizing response steps: Orchestration helps ensure that similar incidents follow the same approved response process, improving consistency and reducing the time spent deciding what to do next.
Used thoughtfully, automation shortens response timelines without removing human oversight from critical decisions.
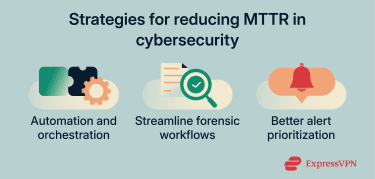
Faster forensic investigation workflows
Determining what happened, how attackers gained access, what they did, and which data was affected often represents a significant portion of MTTR, especially for complex incidents. Inefficient data collection or unclear workflows can extend resolution time.
Streamlining forensic processes can help by:
- Making relevant logs and telemetry easier to access: Centralizing and organizing data helps investigators quickly find the information they need without manually pulling logs from multiple systems.
- Standardizing evidence collection across systems: Consistent collection methods ensure evidence is gathered in the same way each time, reducing confusion and making investigations easier to compare and validate.
- Reducing duplication between investigation and remediation steps: Clear handoffs and shared workflows prevent teams from repeating the same data collection or analysis tasks during response and recovery.
Forensic workflows can be streamlined through tools, processes, and preparation. These include centralized log management and SIEM platforms, EDR and digital forensics tools, predefined incident response playbooks and forensic checklists, integrated case management and ticketing systems, and automated evidence collection and enrichment workflows.
Better alert prioritization
Poor prioritization can slow down response time. When analysts are overwhelmed by low-quality or low-risk alerts, meaningful incidents may take longer to reach the right teams, significantly extending MTTD and MTTA.
Improving alert prioritization helps reduce MTTR by:
- Ensuring high-impact incidents are addressed first.
- Reducing time spent triaging false positives.
- Aligning response urgency with actual risk.
The most important factors to consider for effective prioritization include alert severity, asset criticality, user context, and alert correlation.
Meanwhile, routine alerts can be handled efficiently through batching, where similar low-risk alerts are grouped and reviewed together rather than handled one at a time, or through automation. This tiered response model can optimize analyst productivity, reduce burnout from alert fatigue, and improve MTTR for incidents that matter most to your organization.
Best practices for effective incident management
The following best practices can help improve coordination and decision-making during high-pressure situations and help maintain consistent MTTR across various incident types.
Strong incident response playbooks
Incident response playbooks outline the steps teams should follow when specific types of incidents occur. They provide structured, repeatable procedures that eliminate uncertainty and wasted time during high-pressure incident response.
Well-designed playbooks typically:
- Define roles and responsibilities at each response stage.
- Include decision points for escalation and containment.
- Reference required documentation and validation steps.
When playbooks are kept up to date and aligned with real-world scenarios, they help shorten response and resolution timelines while maintaining consistency.
Regular red-team and blue-team exercises
Red-team and blue-team exercises simulate attacks and defensive responses, providing insight into how well existing controls and workflows perform. The red team attempts to compromise systems, move laterally, and achieve objectives just as real attackers would, while the blue team tries to detect and respond to the simulated attack using standard procedures and tools.
Cross-functional coordination
Security incidents often involve more than one team. Legal, IT operations, communications, and leadership may all need to be involved, depending on the situation. Poor coordination among these groups can lead to unnecessary delays.
Clear communication channels and predefined responsibilities help reduce waiting time for approvals or decisions, prevent duplicate or conflicting actions, and keep response efforts aligned with organizational priorities.
Run regular cross-functional exercises to test coordination mechanisms before real incidents occur. Include representatives from all relevant departments in tabletop exercises and simulations. Walk through realistic incident scenarios together, practice sharing information, and make time-sensitive decisions such as who needs to be notified, who has authority to approve actions, and how updates are communicated.
These exercises reveal communication gaps, unclear responsibilities, and missing procedures that can be addressed. They also build relationships and familiarity across teams, facilitating smoother coordination during actual incidents.
Tools that influence MTTR
Security tools play a supporting role in how quickly incidents are detected, analyzed, and resolved. While they don’t guarantee fast response, the right combination can reduce manual effort, improve visibility, and help teams move through incidents more efficiently.
SIEM and SOAR platforms
SIEM platforms centralize logs and alerts from firewalls, endpoints, applications, cloud services, and network devices, giving teams a unified view of security activity. This visibility helps analysts detect patterns and investigate incidents without switching between systems.
Security orchestration, automation, and response (SOAR) platforms build on this by automating common workflows.
Where SIEM detects threats, SOAR responds to them by executing automated playbooks, orchestrating tools, and managing cases.
Together, these tools can reduce MTTR by:
- Correlating alerts to reduce investigation time.
- Centralizing search and analysis capabilities.
- Automating enrichment and containment steps.
- Standardizing response actions across incidents and security tools.
EDR and XDR systems
EDR tools can reduce MTTR by identifying malicious behavior patterns that signature-based antivirus software might miss.
EDR also enables rapid remote response. Security teams can isolate compromised endpoints, terminate malicious processes, remove malicious files, and collect forensic evidence without physical access. This is especially important for distributed and remote work environments.
Extended detection and response (XDR) builds on EDR by correlating telemetry across endpoints, networks, cloud environments, and applications. This broader visibility helps detect sophisticated, multi-stage attacks earlier.
Threat intelligence integrations
Threat intelligence adds context to alerts by linking observed activity, such as unusual login attempts, suspicious network traffic, or malicious file behavior, to known attack indicators, techniques, or campaigns. When integrated into detection and response workflows, this context helps analysts understand what they’re dealing with more quickly, speeding up decision-making.
To get the most out of threat intelligence integration, consider connecting intelligence feeds to your SIEM, EDR, firewall, and other security tools so automated enrichment occurs instantly when relevant events are detected. This automation ensures intelligence informs every stage of incident response without requiring manual analyst effort.
Network monitoring and anomaly detection tools
Network monitoring tools provide insight into traffic patterns, connections, and anomalies that may indicate malicious activity. Early detection at the network level can shorten the time it takes to recognize and contain incidents.
These tools help reduce MTTR by identifying unusual behavior before it escalates, helping teams scope incidents more accurately, and enabling validation during recovery and resolution.
For distributed and cloud environments, network monitoring must extend beyond traditional on-premises networks to include cloud traffic, remote user connections, and inter-cloud communication.
Cloud-native network monitoring tools and virtual network sensors ensure consistent visibility regardless of where workloads operate, maintaining effective detection and response capabilities across hybrid infrastructure.
FAQ: Common questions about MTTR in cybersecurity
What is MTTR in cybersecurity?
MTTR in cybersecurity is a metric that measures how long it takes to handle a security incident. Depending on the context, it can represent mean time to repair, respond, recover, or resolve. The metric helps organizations evaluate their incident response efficiency and identify areas for improvement in their security operations.
What is a good MTTR?
There’s no single mean time to repair/respond/recovery/resolve (MTTR) value that’s considered “good” for every organization. An appropriate MTTR depends on incident severity, system criticality, and operational complexity. In practice, a good MTTR is one that consistently meets internally defined targets for each incident category and improves over time for similar incident types.
What's more important: MTTR or MTTD?
Mean time to repair/respond/recovery/resolve (MTTR) and mean time to detect (MTTD) are equally important. MTTD measures how quickly an incident is detected, while MTTR measures how long it takes to contain, remediate, and recover after detection. Both metrics address different stages of an incident and are most useful when evaluated together.
How is MTTR different from MTBF?
Mean time to repair/respond/recovery/resolve (MTTR) measures the time it takes to resolve an incident after it occurs. Mean time between failures (MTBF) measures the time between incidents. MTBF reflects reliability and prevention, while MTTR reflects response and recovery effectiveness. The two metrics provide different insights and are most useful when tracked together.
What are the roles of MTTD and MTTA?
Mean time to detect (MTTD) measures how long threats remain undetected in your environment before being discovered, while mean time to acknowledge (MTTA) measures how quickly it’s triaged and assigned after detection. These metrics represent earlier stages of the incident response lifecycle and directly influence mean time to repair/respond/recovery/resolve (MTTR). Delays in detection or acknowledgment often lead to longer resolution times.
How can organizations improve MTTR?
Organizations can reduce mean time to repair/respond/recovery/resolve (MTTR) by improving alert quality, automating repetitive response steps, defining clear incident response playbooks, and streamlining investigation workflows. Regular testing and clear cross-team coordination also help remove delays that extend resolution time.
Why does MTTR matter in incident response?
Mean time to repair/respond/recovery/resolve (MTTR) helps organizations understand how efficiently they handle security incidents. Shorter resolution times generally mean reduced operational disruption, lower exposure windows, and more predictable recovery. When measured consistently, MTTR also helps teams identify process gaps and track improvements in response time.
Which tools help track MTTR?
Tools that support centralized logging, incident tracking, and response workflows make mean time to repair/respond/recovery/resolve (MTTR) easier to measure and analyze. These typically include platforms for event management, response automation, endpoint visibility, and network monitoring. The key factor is consistent data collection and clearly defined start and end points for measurement.
Does network security affect MTTR?
Network security impacts mean time to repair/respond/recovery/resolve (MTTR) by preventing incidents and simplifying response when they occur. Strong network security through encryption and access controls reduces incident frequency, allowing security teams to focus on fewer, more critical threats. Network segmentation limits incident spread, reducing the scope of containment and the complexity of investigations. Network monitoring tools accelerate detection and provide investigation context.
Comprehensive network security enables faster, more efficient incident response across all phases of the security lifecycle.
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN