What is machine learning? Understanding its significance and applications



Machine learning (ML) powers many of the apps, online services, and devices people use every day. It enables ride-sharing services, drives personalized recommendations on streaming platforms, and helps smart assistants respond quickly and accurately.
But though ML is woven into daily life, it can feel abstract or overly technical from the outside. This guide offers a clear, practical overview of what ML is, how models are developed, the main types of algorithms, and where they show up in the real world, so you can see how it all fits together behind the scenes.
What is machine learning in simple terms?
Machine learning (ML) is a branch of artificial intelligence (AI) in which algorithms are trained on data to create models that identify patterns and relationships. These models can then generalize from what they’ve learned to make predictions or decisions on new data without being explicitly programmed for each scenario.
How machine learning works
ML involves building mathematical models that map input features to outputs (predictions). During training, the model analyzes data, evaluates its predictions using a loss function (a measure of how far its predictions are from the correct answers), and iteratively adjusts its internal parameters to minimize error until performance stabilizes.
When trained on data that accurately reflects real-world conditions, the model can generalize its learned patterns to new, unseen inputs once deployed.
That said, a lot goes on in the background for this to happen. The sections below outline the key steps in the ML process:
Data collection and preparation
The ML process begins by defining the objective and identifying the data needed to support it. Based on this objective, data scientists and engineers locate and collect relevant information from sources such as databases, files, APIs, or external platforms.
Depending on the use case, this can include structured tabular data or unstructured data such as images, audio files, and video recordings. In many cases, this stage involves labeling or annotating data so the model can learn which patterns correspond to specific outcomes.
Before being fed to a model, the data must be cleaned, as its quality directly affects prediction accuracy. At this stage, data scientists or automated pipelines review the aggregated data, spot anomalies, and define a consistent structure. They also address data integrity issues such as missing values, inconsistencies, or outliers, which are data points that differ significantly from the rest of the dataset.
Once cleaned, the data is transformed into formats suitable for ML algorithms. This may involve encoding categorical variables, normalizing numerical values, or converting unstructured data such as text or images into structured numerical representations. Finally, the dataset is divided into subsets, typically training and evaluation sets, to support proper model development and testing.
Training and improving a model
Once the training dataset is prepared, the team selects an appropriate model type based on the problem being solved. This defines the mathematical structure that will be used to represent patterns in the data.
At this stage, a learning algorithm is applied to the model, and the training dataset is provided as input. The algorithm uses this data to iteratively adjust the model’s internal parameters so that its predictions increasingly align with the known outputs.
Using its current internal settings, the model generates predictions from the input features. These predictions are compared to the known outputs, and the difference between them is calculated as error using a loss function. Based on this error, the algorithm updates the model’s parameters to reduce future discrepancies.
The updated parameters are then used to generate new predictions, which are evaluated again. This cycle of prediction, error measurement, and parameter adjustment repeats across many iterations of the dataset.
Over time, the model’s internal values are refined so that its predictions increasingly align with the expected outcomes. When the training process reaches predefined stopping conditions, such as stabilized loss or a maximum number of iterations, the model is considered trained.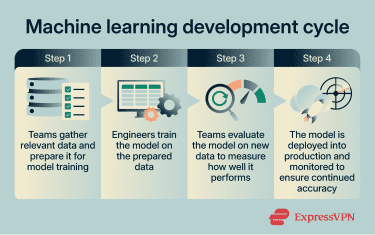
Testing accuracy and performance
Training and evaluation usually happen side by side. As the model learns from training data, its performance is regularly checked using a separate portion of data that it hasn’t seen before.
This helps the team see whether the model is genuinely learning patterns or simply memorizing examples. If performance is strong on both, the model is likely generalizing well. If it performs well only on the training data but poorly on new data, this may indicate it’s learned the training examples too specifically.
Once the team is satisfied that the model performs consistently, it fixes the model’s learned parameters, which means they stop it from updating its internal settings. At this point, the model no longer adjusts or learns from new data; it simply applies what it has already learned.
The team then runs a separate test dataset that was intentionally withheld throughout training to estimate how well it’ll likely perform in real-world use.
Teams may further improve performance by fine-tuning the model. This typically involves continuing to train an already trained model on additional data or adjusting certain learning settings, such as how quickly it updates itself.
Deployment and monitoring
Once the model meets performance expectations, the team deploys it into a production environment where it can begin making real-world predictions. Deployment typically involves integrating the model into an application, service, or system, such as a web platform, mobile app, internal analytics tool, or automated decision pipeline.
Deployment can also vary based on an organization’s IT systems and development frameworks. In most cases, the process includes the following steps:
- Planning the deployment process by ensuring the ML model is production-ready, selecting a deployment method, and assessing required compute resources.
- Performing the necessary setup, such as applying security controls, configuring production environment settings, and installing required dependencies.
- Packaging the model with its dependencies to ensure consistent performance across environments.
- Using sample datasets to confirm the model meets key evaluation metrics and integrates properly with the production environment.
- Continuously monitoring the model after deployment to track model drift, where performance degrades due to changes in data.
- Implementing automated workflows to streamline model updates and ongoing improvements.
In production, the model receives live input data and generates predictions in real time or in scheduled batches. Unlike during training, the model doesn’t update itself automatically but applies the learned patterns to new data as it becomes available.
Monitoring is a critical part of this stage, too. Teams continuously track performance metrics to ensure the model remains accurate and reliable over time. They also monitor for issues such as data drift or performance degradation. If performance declines, the team may retrain the model using more recent data or adjust its configuration.
Types of machine learning
Depending on the type of algorithms and their applications, ML can generally be classified into five broad categories: supervised, unsupervised, reinforcement, semi-supervised, and self-supervised learning.
Supervised learning
Supervised learning is an ML approach that trains models using labeled data. Each training example includes both input features and the correct output (also called “ground truth”), allowing the model to learn a direct mapping between the two. In many cases, humans generate or verify these labels, which is why the approach is described as “supervised.”
Because the correct outputs are known during training, the model uses them as a reliable reference for accuracy, compares its predictions to the ground truth, and calculates error. This feedback guides the model’s parameter updates and helps it improve over time.
For example, if you train a model on images labeled as cars or bicycles, it learns the patterns that distinguish the two categories. When presented with a new image, it applies what it has learned to classify it.
Supervised learning is generally used for risk assessment, predictive analytics, image recognition, and fraud detection. For instance, it may be used to train models that power CAPTCHA tests, predict energy usage for commercial buildings, or help with tornado forecasting.
Unsupervised learning
Unsupervised learning uses unlabeled datasets that include input features but not outputs. Because there’s no correct output to guide the model and give it feedback as to the correct answers, the model examines the dataset to uncover patterns, relationships, or natural groupings within the data.
As it processes the dataset, the model may cluster similar data points together, reduce the number of variables while preserving important structure, or identify associations between features.
An example would be giving the model a collection of images without any labels but specifying that the images should be divided into ten groups. The model would then analyze similarities between the images and decide how to split them into ten clusters without any guidance about the correct categories.
By uncovering hidden structure in complex datasets, unsupervised learning supports applications such as customer segmentation, anomaly detection in industrial systems, medical imaging analysis, and recommendation engines based on user behavior.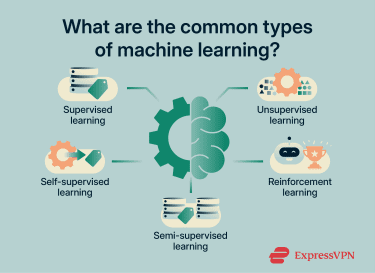
Reinforcement learning
In reinforcement learning, a model is trained within an autonomous, decision-making system called an agent. The agent interacts with its environment by taking actions and observing the results.
The environment defines the possible actions available at each step. As the agent interacts with that environment, it receives feedback in the form of rewards or penalties. Using this feedback, the model updates its internal parameters so that the agent increasingly favors actions that lead to higher cumulative rewards while still exploring new actions to improve performance.
Reinforcement learning models are commonly used to help robots perform autonomous tasks, support self-driving cars in making real-time decisions, and enable non-playable characters in video games to adapt and respond intelligently.
Semi-supervised learning
Semi-supervised learning combines labeled and unlabeled data during training: a small portion of the dataset includes ground truth labels, while a larger portion remains unlabeled. The model uses the labeled data to learn an initial mapping between inputs and outputs, then leverages patterns in the unlabeled data to improve its understanding of the overall data structure.
Semi-supervised learning is especially useful when labeled data is expensive or time-consuming to obtain, but large amounts of unlabeled data are readily available. Common applications include text classification with limited annotated examples, customer feedback analysis, and web page categorization with minimal manual labeling.
Self-supervised learning
In self-supervised learning, the model generates its own training signals from unlabeled data. Instead of relying on manually provided labels, the model creates prediction tasks directly from the structure of the data.
For example, a model might predict missing words in a sentence, reconstruct hidden parts of an image, or forecast the next element in a sequence. Because the correct answers are derived from the data itself, the model can calculate error and update its parameters without human annotation.
Self-supervised learning is widely used in natural language processing, computer vision, and representation learning. Many large language models (LLMs) and modern image recognition systems rely on self-supervised pretraining before being fine-tuned on smaller labeled datasets.
Common machine learning tasks and models
ML systems are designed to solve various types of problems. The nature of the problem determines the type of output the model is expected to produce. Some of the most common task types include:
- Regression: Predicting continuous numerical values. The output is a quantity, such as price, temperature, duration, or probability, and the goal is to estimate a value along a numeric scale.
- Classification: Assigning inputs to predefined categories. The output is a label, such as "fraudulent" or "legitimate," "spam" or "not spam," or "approved" or "denied."
- Clustering: Grouping data points based on similarity without predefined labels. The goal is to uncover structure or natural groupings within the data.
- Anomaly detection: Identifying data points that differ significantly from typical patterns. These unusual observations may indicate errors, rare events, or potential risks.
Machine learning models and training algorithms
ML systems rely on two core components: model architectures and training algorithms. A model architecture defines how predictions are generated from input data, while a training algorithm determines how the model’s internal parameters are adjusted during learning.
When building a system, teams choose both a model type and a training algorithm based on the task they are solving, the amount and type of data available, and practical constraints such as speed or interpretability.
Below are several foundational approaches that form the basis of many ML systems:
Linear models
A linear model makes predictions by combining input values in a straightforward mathematical way. It calculates an output by assigning a fixed contribution to each input feature and adding those contributions together.
Mathematically, the model represents the output as a straight-line relationship between inputs and the target variable. In one dimension, this relationship appears as a straight line. In higher dimensions, it forms a flat surface (a plane or hyperplane).
Decision trees
A decision tree is a model that makes predictions by applying a sequence of conditional rules organized in a tree-like structure.
During training, the algorithm builds the tree by repeatedly splitting the dataset into smaller groups based on feature values. At each step, it evaluates possible splits and selects the one that best separates the data according to the target outcome. This process continues until further splitting no longer meaningfully improves the model’s performance or a stopping condition is reached.
The result is a tree composed of decision nodes and leaf nodes. Decision nodes contain learned rules about input features, and leaf nodes store the final predicted value or category.
During prediction, new data enters the tree at the top. The model evaluates the learned rules one step at a time, following the appropriate branch at each decision node until it reaches a leaf node. The value stored in that leaf becomes the model’s prediction.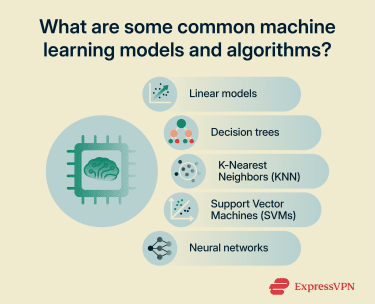
K-Nearest Neighbors (KNN)
The K-Nearest Neighbors (KNN) model makes predictions by analyzing the similarity between data points. The model stores the training data along with the known outcomes. Each data point is represented as a position in a multi-dimensional space, where each dimension corresponds to one input feature.
When a new data point needs a prediction, the model calculates the distance between that point and all stored examples using a defined distance metric. It then identifies the K closest data points, which are its nearest neighbors.
The value of K determines how many neighbors influence the prediction. Smaller values make the prediction more sensitive to local patterns, while larger values produce smoother results.
Support Vector Machines (SVMs)
The SVM model separates data into distinct groups by identifying a boundary between them. It analyzes how data points are positioned relative to one another and determines the dividing line or surface that creates the widest possible gap between groups.
The data points closest to this boundary determine its exact placement. These points are called support vectors because they effectively “support” or define the position of the boundary.
If the data can’t be separated by a simple straight line, the SVM can transform the data into a different mathematical representation where a clear separation becomes possible. Although commonly used for classification tasks, SVMs can also be adapted for predicting numerical values by fitting a function that stays within a defined margin around the data points.
Neural networks
Neural networks make predictions by passing input data through multiple layers of interconnected computational units. Each layer transforms the input into a new representation by applying mathematical operations. The output of one layer becomes the input to the next. As data moves through the network, these transformations allow the model to capture increasingly complex patterns.
Training strategies
In practice, a single model isn’t always sufficient to capture all patterns in a dataset. Even well-designed models can make systematic errors, overfit certain examples, or miss subtle relationships.
Ensemble methods address this limitation by combining multiple models into a single system. Rather than relying on one prediction, they aggregate the outputs of several models to produce a more stable and accurate result.
There are several common ensemble strategies:
- Bagging: Trains multiple models in parallel on different randomly selected subsets of the training data, then combines their outputs through voting or averaging.
- Stacking: Trains multiple models and uses their predictions as inputs to a final model, which learns how to combine them effectively.
- Boosting: Involves training models in sequence, with each new model focusing on correcting the errors made by previous ones.
In many modern LLMs, teams use architectures known as Mixture-of-Experts (MoE). These systems build a single model that contains multiple specialized components. For each input, a routing mechanism selects which components to use. This allows different parts of the model to specialize in handling different types of patterns or tasks. Unlike traditional ensemble methods, which combine independently trained models, MoE architectures train all components together as part of one unified system.
Machine learning applications across industries
ML is widely used across many industries and sectors. Below are a few examples of real-world applications that are part of everyday life:
- Healthcare: ML is used to develop treatment plans from patient medical records, support genetic research by identifying how genes influence health, and improve medical imaging by detecting conditions that might be missed.
- Finance: Banks and financial institutions use ML models to detect suspicious transactions or unusual spending patterns. They also use predictive models to assess loan eligibility, forecast market movements, and support algorithmic trading with minimal human intervention.
- User experience: Many online platforms use ML algorithms to deliver personalized recommendations, such as movies, songs, or products, based on user behavior. Online services also apply ML in customer support to power chatbots.
- Marketing: Marketing and sales teams use ML models to generate leads, analyze customer data to understand buyer personas and intent, and improve search engine optimization (SEO) strategies.
- Cybersecurity: Organizations employ ML models to strengthen authentication systems, detect and respond to cyberattacks, and classify phishing attacks. Security tools, like antivirus software, also leverage ML algorithms to detect malware.
- Smart assistants: ML algorithms power text and voice assistants, enabling features such as speech recognition, speech-to-text conversion, voice transcription, and text-to-speech generation.
- Transportation: ML models help apps analyze traffic conditions, determine the fastest routes, recommend nearby places to visit, and match drivers with passengers in ride-sharing services. They also enable self-driving cars to interpret data from cameras and sensors, understand their surroundings, and make real-time driving decisions.
Privacy and security in machine learning
Attackers increasingly target ML models because they rely on and process large volumes of valuable data. At the same time, ML projects raise privacy concerns due to the scale of data collection and its potential long-term impact on user privacy.
Risks in data collection and storage
ML-powered hardware, apps, and services heavily rely on data harvesting, which involves collecting extensive details about people, devices, and businesses. This makes sense, as ML models require large volumes of relevant data to optimize performance, deliver accurate predictions, and take correct real-time actions.
However, extensive data collection can include personal details such as email addresses, real-time location, shopping history, healthcare information, and browsing habits. This raises privacy and ethical concerns, as people may worry about how much sensitive information is collected, how it’s used, who has access to it, and how it affects their long-term privacy. Concerns also arise when data is collected or used without clear user consent.
Furthermore, ML-powered systems are often prime targets for cybercriminals because they collect and store so much valuable data. Malicious actors may attempt to extract sensitive information or compromise model behavior using techniques such as model inversion, membership inference, model extraction, data poisoning, or evasion attacks.
Data breaches are another concern, as ML models may unintentionally expose sensitive user information, such as medical records or private messages. Weak security frameworks and human error can also lead to data leaks that reveal valuable information.
Privacy risks during model training
ML models are trained on large-scale datasets to optimize accuracy and performance. That data is acquired from various sources, including voluntary data donations, interactions with AI systems, and open data initiatives. Privacy concerns arise when development teams acquire information from data brokers, news outlets, social media platforms, or websites using data scraping, as this type of collection may include large amounts of personal details.
Weak access controls may also lead to privacy issues, as unauthorized users or insider threats could take advantage of poor authentication and security frameworks. If bad actors gain access to ML training data, they could steal it or tamper with it, which can lead to compromised models and unreliable outcomes.
Attacks on deployed models
Malicious actors are increasingly targeting ML models after deployment with sophisticated attacks to gain unauthorized access to sensitive data or compromise how the models function.
Common types of attacks include:
- Membership inference attack: Repeatedly queries a trained model to determine whether specific data points were part of its training dataset, which can expose sensitive information.
- Model inversion attack: Attempts to reconstruct or extract sensitive training data by reverse-engineering the model.
- Adversarial AI attack: Feeds intentionally misleading inputs to the model to trigger incorrect, insecure, or unintended behavior.
- Supply chain attack: Targets the ML development pipeline by compromising third-party packages or libraries and using them to introduce malicious code.
Safeguards and mitigation strategies
To protect ML projects from cyber threats and reduce privacy risks, organizations should enforce strong privacy controls and security frameworks. Best practices include:
- Risk assessment: Potential privacy risks should be assessed and addressed throughout the ML lifecycle, including risks that may affect people who don’t use the system but whose data may be included in training datasets.
- Limited data collection: Organizations should collect training data only from legitimate sources and apply clear data retention policies so sensitive information is removed as soon as it’s no longer needed.
- Explicit consent: Companies should give users control over their data and use clear consent mechanisms when collecting information. If the purpose for collecting the data changes, they should obtain consent again.
- Adversarial training: This is a defense method in which teams add adversarial examples with the correct labels to the training data so the model learns to resist misleading inputs.
- Strong security models: Organizations should implement reliable security frameworks to protect network and ML assets and resources, like zero-trust network access (ZTNA) models that require continuous identity verifications.
- Strict access controls: Security teams should strictly review and control access to ML systems and resources to ensure only authorized users can interact with sensitive datasets.
FAQ: Common questions about machine learning
Do you need to code for machine learning?
What is the difference between AI and ML?
What is the difference between machine learning and deep learning?
What industries use machine learning?
What are the common challenges in implementing machine learning?
How does machine learning impact society?
What is the future of machine learning?
What is the best way to get started with machine learning?
As you progress, you can explore additional tools or languages depending on your interests, such as the R programming language, which is commonly used for statistics and data analysis, or C++.
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN