What are generative adversarial networks (GANs)?



Generative adversarial networks (GANs) are a type of deep learning model that can generate synthetic data resembling real-world data. They’re typically used to generate images, though they’ve also been explored for text and audio generation.
In this article, you’ll learn about how generative adversarial networks work, their types and applications, their drawbacks, and the challenges involved in implementing them.
What is a generative adversarial network (GAN)?
A GAN is a deep learning model consisting of two neural networks (a generator and a discriminator) that compete during training to improve the realism of the generator’s data. The discriminator’s primary role is to train the generator, and it’s not needed after training ends. GANs typically rely on unsupervised learning to analyze unlabeled data and find patterns without human intervention, although some models (like class conditional GANs) rely on supervised training.
These models played a key role in advancing modern AI image generation, and they’re widely used across several other areas too, such as super-resolution (upscaling low-resolution images) or distillation (using a larger model’s outputs to train a smaller model). GANs are less often used for video generation and text-to-image synthesis, as that role is largely fulfilled by diffusion models.
Why GANs matter
GANs introduced a new approach to training generative models; instead of trying to mathematically describe how real data is structured, they train two neural networks in opposition: the generator and the discriminator.
The generator produces synthetic data from random noise, while the discriminator analyzes whether a data sample comes from the real training dataset or was generated artificially by the generator network.
This setup lets the generator improve by learning directly from the discriminator’s feedback. Compared to previous generative approaches that relied on likelihood estimation (explicitly learning a probability distribution and assigning higher probability to the training data) or sequential prediction (generating outputs one element at a time based on previous elements), GANs can produce sharp, highly realistic artificial samples without needing explicit probability modeling.
This adversarial architecture has significantly influenced generative modeling and the development of image synthesis, super-resolution, and other media-creation techniques. It’s also proven that competitive neural network training can produce artificial data at scale.
How GAN training works
GAN training is the iterative process by which a generator and a discriminator neural network are trained together to improve artificial data generation.
Adversarial training process: Step-by-step
The training process begins with inputs and data preparation. Researchers assemble a large dataset containing real examples of the type of data the model is meant to generate (such as images, audio, or text). This dataset serves as the reference distribution that the model learns to imitate.
In addition to real training data, the generator receives random input vectors (often called latent noise), which are generated during runtime and transformed into synthetic data samples.
Then, the actual training cycle begins:
- The generator creates a batch of synthetic data from latent noise.
- The discriminator evaluates both real samples from the dataset and synthetic samples from the generator, attempting to determine which are genuine and which are fake.
- The discriminator updates its parameters based on its classification error, a measure of how far its predictions (real vs. fake) differ from the correct labels.
- The generator updates its parameters using gradients derived from the discriminator’s output. Gradients indicate how the generator’s parameters should change to reduce the error and make its outputs more likely to be classified as real.
This cycle repeats over many iterations. As one network improves, it increases the difficulty for the other, forcing it to adapt. This feedback loop gradually improves both networks, with the goal of approaching a training equilibrium known as a Nash equilibrium.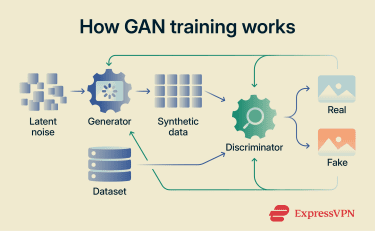
Loss functions and the training objective (minimax)
The goal of a GAN is to train a generator that can produce realistic synthetic data that’s difficult to distinguish from real data. Successful training tends to reach a state where:
- The discriminator’s accuracy in its assessments of the generator’s outputs approaches random guessing, indicating that generated samples closely resemble real data.
- The discriminator is discarded, as its goal was achieved (to help in the creation of a generator that can successfully deceive it).
The performance of the generator and discriminator is determined by the latter’s loss function, which measures how effectively it can identify fake data from real data. This is called a “minimax,” and it plays out like this:
- The generator tries to maximize the discriminator’s loss by synthesizing data sufficiently similar to the real data that the discriminator can’t tell them apart.
- The discriminator tries to minimize its own loss function, which means that it can accurately identify data from the real dataset, as well as identify the generator’s fake data.
 This process is dynamic: the generator can temporarily get better at fooling the discriminator, decreasing its loss function while the discriminator’s loss increases, but the discriminator is also constantly improving and posing a greater challenge to the generator, which shifts the balance between the two networks during training.
This process is dynamic: the generator can temporarily get better at fooling the discriminator, decreasing its loss function while the discriminator’s loss increases, but the discriminator is also constantly improving and posing a greater challenge to the generator, which shifts the balance between the two networks during training.
Common GAN training challenges
GANs are used in applications such as art creation, image super-resolution, and image-to-image translation (transforming one type of image into another while preserving its core structure, such as turning sketches into photos). However, it’s important to know that they’re prone to several common failure patterns.
| Failure pattern | What it means |
| Mode collapse | The generator produces limited or repetitive outputs, focusing on a narrow set of samples that consistently fool the discriminator. As a result, the model fails to capture the full diversity of the training data. |
| Vanishing gradients and imbalance | If the discriminator becomes too efficient, it can easily distinguish real from generated data. In this case, the generator receives little useful feedback and stops improving. Alternative loss functions and training strategies have been proposed to mitigate this issue. |
| Training instability and non-convergence | The generator and discriminator may oscillate during training, causing loss values to fluctuate and preventing the model from reaching a stable Nash equilibrium. This is often influenced by hyperparameters, architecture design, or data distribution. |
| Evaluation difficulty | Measuring the quality and diversity of GAN outputs is challenging because there is no single ground-truth target for comparison. Unlike supervised learning tasks, evaluating realism and variety often requires indirect metrics or human judgment. |
| Computational resources | Training large, state-of-the-art GANs can require significant computational resources and extensive experimentation, particularly for high-resolution image generation. |
Researchers have proposed various techniques to improve training stability and diversity. These include alternative objective functions such as the Wasserstein loss and gradient penalties to stabilize the discriminator. While these approaches can reduce instability and mode collapse, GAN training still remains sensitive to hyperparameters.
Types of GANs
There are multiple GAN examples, depending on how the generator and discriminator interact and how the training objective is defined.
Vanilla GAN
A vanilla GAN is the simplest type of generative adversarial network, where a generator creates fake data and a discriminator analyzes it to distinguish if it’s fake or real. These GANs use multilayer perceptrons (MLPs), fully connected neural networks made up of an input layer (which receives the data), one or more hidden layers (which learn patterns through weighted connections and activation functions), and an output layer (which produces the final prediction or generated result).
This type of GAN tends to be unstable during training and needs significant hyperparameter tuning to perform well in more complex tasks. Vanilla GANs are especially vulnerable to mode collapse and training issues, as the generator and discriminator might not improve linearly.
Deep convolutional GAN (DCGAN)
Deep convolutional GANs use convolutional neural networks (neural networks designed for processing visual data) to increase the model’s efficiency in image generation. This type of model has better spatial understanding, as it removes fully connected layers (layers where every neuron is connected to every neuron in the previous layer), and it implements convolutional layers for the generator and discriminator.
Simply put:
- The generator receives random noise as input and uses transposed convolutions to “zoom into” the noise and get an upscaled, detailed image.
- Discriminator uses convolutional layers to “zoom out” of the noise and analyze its overall structure to determine if the image is real or fake.
DCGANs were introduced to improve training stability and reduce issues like mode collapse. By using convolutional and transposed convolutional layers and batch normalization, a technique that normalizes layer inputs during training to stabilize gradients and speed up convergence, DCGANs make training more reliable for both the generator and the discriminator.
Conditional GAN (cGAN)
Conditional GANs add another parameter (or label) to optimize the generation process with more context for the generator and discriminator. This allows for targeted data generation instead of completely random noise (used in vanilla GANs).
This means that the generator can be instructed to create a “specific” type of image instead of “any” image or to turn a black-and-white image into a colored image. The discriminator also receives this additional label, which helps it distinguish fake from real data within the new context that the generator is creating images in.
This makes cGANs particularly useful for tasks that require precision and fine-tuned control, like generating images from text or creating images based on specific instructions. Computer vision is another practical application of cGANs, as it allows the AI to analyze, understand, and make contextual decisions based on the visual input provided to it.
CycleGAN
CycleGANs are used for unpaired image-to-image translation. They can change the style of an image (like turning a realistic photo into a pixelized version of it or turning a horse into a zebra) without requiring paired training examples.
Unlike standard GANs, CycleGANs reduce degenerate one-to-many mappings: situations where many different input images (for example, different horses in different poses and environments) are mapped to the same or very similar output image (such as one “typical” zebra).
In the horse–zebra example, an autoregressive model (which produces outputs step by step, for example, pixel by pixel or token by token, by predicting each next value based on previous ones) working with no matching image pairs (for a horse and a zebra) may fail to preserve input structure or learn a meaningful conditional mapping.
For instance, it might take a photo of a running horse and output a generic standing zebra with a different pose, background, or body proportions, because it has only learned what zebras look like in general rather than how to transform that specific horse.
A CycleGAN adds a constraint: the model must be able to convert the zebra output image back into the original horse image. This encourages the model to maintain meaningful visual structure. To continue with the horse–zebra example, if the original horse is facing left with one leg raised, the generated zebra must preserve that orientation and pose so that the reverse mapping can reconstruct the same left-facing horse with the raised leg rather than ignore the input or learn only the marginal distribution of the target domain, which in this case would mean generating an “average-looking” zebra regardless of the specific horse provided.
While CycleGANs are efficient at modifying textures, patterns, and colors, they struggle with significant changes to an object’s shape or structure. Sometimes, they may provide unpredictable outputs, which make the final image look unnatural or distorted.
Performance evaluation typically happens through perceptual studies, where real people review the images and determine if they look real or not.
StyleGAN
StyleGAN is a GAN architecture designed to generate highly realistic, high-resolution images. It improves on earlier GAN models by changing how the generator uses its random input.
Instead of feeding the noise directly into the network, StyleGAN first transforms it, then injects that information into multiple layers of the generator.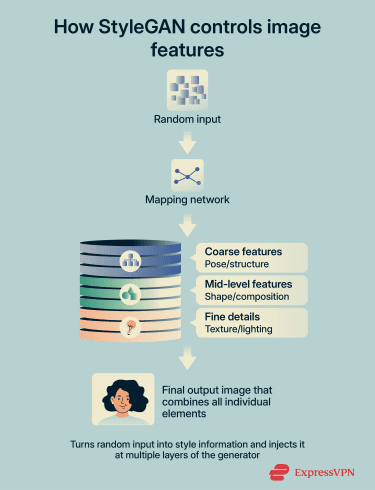
Because different layers of a neural network control different levels of image detail, this allows a StyleGAN to influence both the overall structure and the fine details of an image more effectively.
Lower layers influence rough attributes like pose and overall structure, while higher layers control finer details like texture and lighting without affecting the entire image. Earlier StyleGAN versions used progressive growing during training to stabilize high-resolution generation, while later versions improved stability through structural refinements rather than adding more layers.
Super-resolution GAN (SRGAN)
SRGANs upscale low-resolution images to higher-resolution ones while avoiding blurriness and stretched pixels and maintaining sharp details that weren’t present in the original image. However, these details are an approximation rather than exact reconstructions, meaning the model predicts realistic textures rather than recovering true information.
In this case, the adversarial game follows the same pattern as a typical GAN. The generator takes a low-resolution image and outputs a high-resolution image, while the discriminator compares a real high-resolution image to the generated one and tries to tell them apart.
This pushes the generator to produce sharper textures and aim for perceptual realism instead of pixel closeness, which often leads to blurry images and the “averaging” effect. Many super-resolution GANs also combine adversarial loss, which encourages realism by trying to fool a discriminator, with perceptual loss, which preserves high-level visual details by comparing feature representations instead of raw pixels.
Common applications of GANs
GANs have been applied in a range of industries and research fields, particularly in computer vision and media creation.
Image generation and editing
A primary use case of GANs is image generation or synthesis (through text prompts). The models can generate high-fidelity images of human faces, objects, landscapes, and more from a given dataset, which can be used in the marketing or entertainment industries. For example, the website ThisPersonDoesNotExist launched in 2019 using StyleGAN, demonstrating how GAN-generated faces could appear highly realistic.
However, in recent years, diffusion technology (used in models like Midjourney or DALL-E) has become more widely adopted for image synthesis and editing.
Image-to-image translation
GAN image-to-image translation can convert the context of an image, such as converting a black-and-white image to color or changing the season in a photograph from autumn to winter.
GANs can also:
- Translate sketches to color photographs.
- Turn a photo into a painting.
- Change the time in a photo from day to night.
- Translate a satellite map into street view, or vice versa.
Super-resolution and restoration
Another important use case for GANs is image restoration through super-resolution. The model can upscale a low-resolution image or video to a significantly higher pixel density by predicting high-frequency details (like textures) and generating plausible details that weren’t visible before.
A successful output will ideally look like an enhanced and higher-resolution version of the original, with no distinguishable differences in features. An important nuance is that these models don’t recover lost information; they generate plausible details that weren’t present in the original image.
Super-resolution GAN models may be used in video upscaling, gaming remastering, satellite image enhancement, or photo enhancement apps. In terms of image restoration, the GAN receives a corrupted image where parts of the image may be missing, and it fills the missing regions with plausible textures (inpainting).
Synthetic data for training other models
GANs can create synthetic data (such as images) that can increase the diversity of the training data for other deep learning AI models. This is especially useful in domains where real data is limited, expensive, or sensitive, like medical imaging, fraud detection, or autonomous driving.
This process is called data augmentation, and while it’s advantageous for supplementing data samples in AI training and other industries, it can amplify biases or reduce diversity if the GAN suffers mode collapse.
Video and 3D content generation
GANs have been used to generate video sequences and 3D objects. In video synthesis, models like MoCoGAN can separate motion and visual content to create short clips, while earlier models like Temporal GAN were used in video modeling.
In 3D generation, 3D-GAN demonstrated that GANs could generate voxel-based object shapes. A voxel (short for “volumetric pixel”) is a small cube that represents a point in three-dimensional space, similar to how a pixel represents a point in a two-dimensional image. By arranging many voxels in a 3D grid, a model can build a rough three-dimensional representation of an object.
Later models could create 3D point clouds, which represent objects as collections of points in three-dimensional space. Instead of filling space with cubes like voxels, a point cloud simply stores the coordinates of many points on an object’s surface, forming a sparse outline of its shape.
While diffusion models are increasingly used for advanced video and 3D generation, GANs were instrumental during the early research phase. They proved that AI models could be used for much more than simple image generation.
Audio or text generation: When GANs fit (and when they don’t)
GAN-based approaches have been explored for audio generation, with notable attempts including the SpecGAN and the WaveGAN, both based on the DCGAN architecture. Although they often produced noticeable artifacts (unintended distortions), they inspired researchers to seek out other implementation methods. Today, diffusion models are more widely used for audio generation.
GANs have also been explored for text generation, specifically in helping train other machine learning models for activities like text summarization, translation, or dialogue systems. However, transformer-based architectures are more commonly used in modern natural language processing (NLP) systems.
Challenges in implementing and using GANs
Other than training-specific drawbacks (such as mode collapse or vanishing gradients), generative adversarial networks may hit obstacles during implementation and real-world usage.
Data quality, bias, and hallucinated artifacts
Some of the more common challenges with GANs include:
- Data quality: Because GANs learn directly from training data, low-quality or imbalanced datasets can negatively affect outputs. Noise, limited sample size, poor labeling, or lack of diversity can reduce realism or cause the model to generalize poorly.
- Bias: A specific consequence of imbalanced training data is bias, where the model reproduces the imbalance or biased patterns present in the dataset. If certain groups or attributes are underrepresented, generated outputs may further underrepresent them.
- Hallucinated artifacts: GANs can introduce visual artifacts or unrealistic textures, particularly when the training is unstable. A commonly discussed example is the tendency of some image-generation models to render extra fingers or distorted hands.
Compute cost and reproducibility
GAN models often require careful hyperparameter tuning and multiple training runs to achieve stable results. Performance can vary significantly depending on tuning choices and random initialization, which can complicate reproducibility and make convergence less predictable than in likelihood-based models trained with standard optimization objectives.
High-resolution GAN architectures, such as StyleGAN2, use deep convolutional layers and can require significant GPU memory and training time when generating high-resolution outputs (for example, 1024×1024 images). However, modern implementations are relatively efficient compared to many newer generative architectures, and models like StyleGAN2 can be trained on consumer-grade GPUs with moderate VRAM requirements.
Training large-scale GANs at high resolution may still involve extended training schedules, particularly when aiming for high visual fidelity and strong distributional coverage. In addition, because GAN training involves both a generator and a discriminator, each training step updates two neural networks. Even though the discriminator is discarded after training, it still contributes to the overall training compute cost.
However, this computational burden applies mainly to the training phase. Compared with many diffusion-based models, GANs are typically much more efficient at inference time (the stage where a trained model generates new images without updating its parameters), since they produce outputs in a single forward pass. Diffusion models, by contrast, generate images through multiple iterative denoising steps and often rely on large U-Net or transformer-based architectures. As a result, GANs often provide significantly faster sample generation, although direct comparisons can be difficult because different models may target different capabilities and levels of output quality.
Ethical and legal considerations
GANs have expanded the capabilities of artificial media generation, particularly in computer vision. However, their ability to produce realistic images, videos, and audio also raises ethical and legal concerns.
From deepfakes and misinformation campaigns to copyright disputes and privacy violations, GAN-based systems require careful oversight and responsible deployment.
Deepfakes and misinformation
Because GANs can generate highly realistic artificial media (such as images or videos), they can be misused to impersonate individuals or fabricate visual evidence. Deepfake technology has been used to manipulate public perception, damage reputations, and spread false information.
A 2024 poll from Deloitte showed that 26% of 2,190 executives said their organization experienced deepfake incidents that targeted accounting and financial data. Even individuals familiar with deepfake technology may struggle to distinguish authentic content from generated material, and AI scams have become increasingly common in recent years.
Consent, privacy, and intellectual property
Many GAN systems are trained on large real-world datasets that may include images, audio, or text collected from public or licensed sources. This can raise questions of consent for users who may not agree to having their likeness used by the AI model. In image generation, outputs may resemble real individuals, even when the model was not explicitly trained on a specific person.
Intellectual property and potential copyright infringement is another gray area. Some artists and content creators have raised concerns about AI companies using their creative work to train models without consent. Furthermore, using a GAN model to reproduce copyright-protected media can have legal consequences.
FAQ: Common questions about generative adversarial networks
What is the purpose of a GAN?
How do GANs work in simple terms?
How do GANs differ from other machine learning methods?
How do GANs differ from diffusion models and VAEs?
What challenges do GANs face in practical applications?
Can GANs generate audio or text, not just images?
What is the most popular GAN variant today?
Is ChatGPT a GAN?
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN