
Expressvpn Glossary
Training data

What is training data?
Training data is the information used to teach AI and machine learning (ML) models to recognize patterns, make predictions, or generate outputs. It typically comes from real-world sources such as text, images, audio, sensor data, browsing activity, and purchase history.
How does training data work?
Training data helps a model learn patterns from examples. In supervised learning, it includes paired inputs and expected outputs, allowing the model to map one to the other. In unsupervised learning, the model identifies patterns or structures within the data.
Before training begins, the data is prepared. It’s collected from relevant sources, then cleaned and normalized to remove errors, duplicates, and inconsistencies.
Next, depending on the learning approach, the data is labeled. In supervised learning, human reviewers or automated tools tag each example with the expected output, such as marking an email as spam or identifying objects in an image. In unsupervised learning, data isn’t labeled, and the model identifies patterns within the data.
The dataset is then split into three parts: a training set for learning, a validation set for tuning, and a test set to evaluate performance on new data.
As the model processes the training data, it adjusts its internal parameters to reduce errors and improve its predictions over time.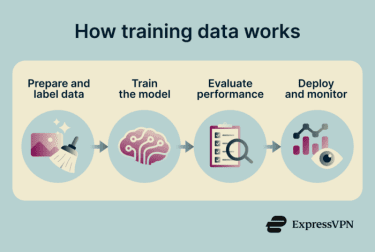
Types of training data
Common types of AI training data include:
- Labeled data: Includes predefined tags that show the model how inputs should be interpreted, helping it learn the relationship between inputs and outputs. Used in supervised ML.
- Unlabeled data: Has no tags or answers. The model identifies patterns on its own. Used in unsupervised ML.
- Reinforcement data: Provides feedback signals instead of labeled examples. The model receives positive or negative feedback based on its actions, such as completing a task correctly or making an error, and learns over time by improving outcomes.
- Synthetic data: Artificially generated data used when real-world data is limited, sensitive, or difficult to collect.
Why is training data important?
High-quality training data helps reduce false positives and false negatives, so models are less likely to misclassify or miss important signals. It also improves generalization, allowing models to perform more accurately on new, unseen inputs.
Training data also affects fairness and safety. If datasets reflect historical bias, models can produce skewed or harmful results, which makes careful data selection and preparation essential.
Where is training data used?
Common use cases for training data include:
- Spam, phishing, and malware detection: Models learn from examples of malicious content to identify and block threats before they reach the user.
- Fraud detection and anomaly monitoring: Systems use training data to spot unusual patterns that may indicate fraudulent activity.
- Face, voice, and image recognition: Computer vision and speech systems rely on large datasets to identify people, objects, or spoken commands.
- Search ranking and recommendations: Platforms train models on user interactions to improve result ranking and generate relevant recommendations.
- Network security and threat analytics: Models trained on network traffic patterns help detect unusual activity that may signal cyberattacks or unauthorized access.
- Generative AI systems: Models are trained on large datasets of text, images, or audio to generate new content, such as writing, artwork, or synthetic media.
Risks and privacy concerns
Training data can include personal or sensitive information. If it’s collected or stored without strong safeguards, it can be exposed.
Training data can also be manipulated. In data poisoning attacks, malicious actors introduce misleading or corrupted data to influence how a model behaves. This can cause inaccurate or unreliable outputs over time.
Organizations can reduce these risks through data minimization, strong anonymization, strict access controls, and techniques like differential privacy, which adds controlled noise to protect individual identities.
Further reading
- How to protect your creative work from AI training
- Data harvesting: What it is and how to stay protected
- What is big data security and privacy?
- Machines are learning, and they know a lot about you
- Is ChatGPT safe? Risks, privacy, and how to use it safely


