
Expressvpn Glossary
Real-time data

What is real-time data?
Real-time data is information collected and made available with minimal delay after it's created. It reflects what is happening now rather than what happened earlier.
The exact delay depends on the system and the use case. In many setups, updates arrive within seconds or milliseconds. There’s no universal maximum delay; data is typically considered real-time when it's delivered quickly enough to meet a specific operational need, sometimes described as real-time or near real-time.
How does real-time data work?
Real-time data systems process information continuously as it arrives from sources such as sensors, applications, or connected devices, rather than only in large scheduled batches.
These events flow through data pipelines that ingest and buffer (or queue) incoming data before processing. Stream processing tools analyze the stream by filtering, aggregating, or enriching events to make the information more useful, including handling cases where events arrive out of order.
The processed results appear through dashboards or application interfaces that update automatically. Many setups use predefined rules to trigger alerts when certain conditions or thresholds are met, allowing systems or teams to respond quickly.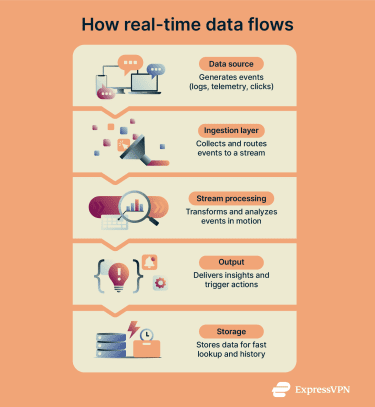
Why is real-time data important?
Real-time data helps organizations understand and respond to events as they unfold. This is especially important in environments where delays can increase risk or cause disruptions. Key benefits of real-time data include:
- Security operations and threat detection: Security operations centers (SOCs) and security information and event management (SIEMs) aggregate logs (records of system events and user actions) from across infrastructure and correlate events to help detect, investigate, and respond to coordinated attacks, malware activity, or unauthorized access.
- Fraud prevention and payment processing: Financial institutions monitor transactions to identify unusual or suspicious patterns and take action (e.g., flagging, declining, or step-up verification), while reducing friction for legitimate transactions.
- Network monitoring and intrusion detection: Systems track traffic patterns, bandwidth usage, and connection attempts to identify distributed denial-of-service (DDoS) attacks, performance degradation, or suspicious access attempts as they emerge.
- Internet of Things (IoT) and industrial monitoring: Connected devices report sensor data from industrial equipment, smart infrastructure, or vehicles to track performance metrics and equipment health in real time or near real time.
- User experience: Streaming services, gaming platforms, and collaborative tools rely on low-latency updates to keep playback smooth, support real-time interactions, and synchronize shared work.
Risks and privacy concerns of real-time data
Real-time data systems can introduce privacy and security risks if not designed and managed properly, such as:
- Sensitive data exposure: Unencrypted (cleartext) data streams can be intercepted or modified during transmission, potentially exposing credentials, financial information, or other sensitive information.
- Over-collection: Capturing more data than necessary increases storage costs, expands the attack surface, and may create compliance obligations under regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA).
- Profiling and tracking: Continuous tracking of user behavior, location data, or device activity can enable detailed profiling of individuals and support intrusive targeted advertising or other secondary uses. If this data is exposed, it may also enable more convincing targeted scams (such as spear phishing).
- Access control failures: Misconfigured permissions or weak authentication can allow unauthorized access to live data feeds, potentially exposing sensitive business intelligence or user activity.
- Data integrity attacks: Attackers may inject or alter events to trigger incorrect alerts, disrupt automated workflows, or conceal malicious activity within normal-looking traffic.
Further reading
- What is an IoT network?
- What is the Industrial Internet of Things (IIoT)?
- IIoT vs IoT: What’s the difference?
- IoT connectivity explained
- IoT infrastructure overview
FAQ
What’s the difference between real-time and near-real-time data?
Near-real-time data arrives with a longer delay that is still close to “live” for the use case, often due to processing steps, buffering/micro-batching, or network latency.


