
Expressvpn Glossary
Differential privacy

What is differential privacy?
Differential privacy is a mathematical method for analyzing large datasets that limits the risk of individuals within that data being identifiable. It ensures that the inclusion or exclusion of a single person’s data doesn’t meaningfully affect the outcome of an analysis, allowing the privacy of individuals to be preserved.
How does differential privacy work?
Differential privacy uses mathematically-defined rules to limit how much information each data point can reveal. It adds noise, or random values, to the results of data queries. This ensures that the results remain nearly identical whether a user’s data is included or excluded, making it difficult to connect data from a specific subject to a specific record.
To prevent attempts to average out the noise through repeated analysis (potentially impacting privacy), differential privacy systems use privacy budgets that restrict how many queries or analyses can be performed.
The noise is optimized to maintain statistical accuracy and reliable insights, enabling organizations to analyze and share sensitive data under a strong and mathematically provable privacy standard.
Key concepts in differential privacy
- Noise injection: The deliberate addition of random values to mask individual contributions.
- Privacy budget: A parameter that controls the trade-off between data accuracy and potential privacy loss.
- Local vs. global differential privacy: Noise is either added directly to the data or to aggregated outputs before sharing.
- Aggregation queries: Queries that focus on summaries or population-level statistics rather than individual records.
- Privacy guarantees and bounds: Rules that limit how much information an analysis can reveal about any individual, even when data is queried multiple times.
Why differential privacy matters
Differential privacy helps protect individuals’ personal information in large datasets by limiting how much information can be obtained. It allows organizations to analyze data without exposing individual records or increasing privacy risk beyond defined limits.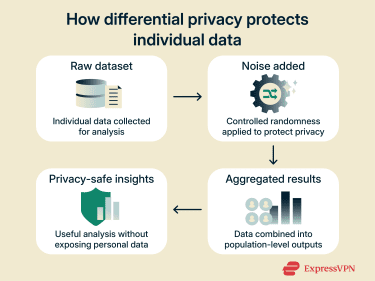 At the same time, differential privacy enables large-scale data analysis in ways that can align with privacy regulations and data protection standards. It supports secure data sharing, reduces exposure from data breaches, and plays an important role in responsible AI and machine learning (ML) practices by reducing reliance on raw personal data.
At the same time, differential privacy enables large-scale data analysis in ways that can align with privacy regulations and data protection standards. It supports secure data sharing, reduces exposure from data breaches, and plays an important role in responsible AI and machine learning (ML) practices by reducing reliance on raw personal data.
How differential privacy impacts privacy and security
- Protects individual records: Differential privacy reduces the risk of records being traced back to a specific individual.
- Reduces reidentification risk: It makes reidentification and inference attacks significantly harder, even when attackers have access to additional data sources.
- Limits data exposure: By adding randomness, it reduces the amount of sensitive information revealed when datasets are shared.
- Supports secure data use: It helps safeguard personal data in research, analytics, and cloud-based environments.
- Big tech adoption: Organizations like Apple, Google, and Meta use these techniques to protect user data at scale.
Common use cases of differential privacy
- Census and population statistics: Used to publish demographic insights while limiting the risk that individuals in the dataset could be identified.
- User behavior analytics: Enables analysis of usage patterns without revealing details about specific users.
- ML model training: Helps train AI models on large datasets while reducing exposure of personal data.
- Public data releases: Allows organizations to share aggregate findings without disclosing individual records.
- Healthcare and financial research: Supports research on sensitive data while maintaining defined privacy protections.
Examples of differential privacy techniques
- Laplace noise mechanism: Adds small and random positive or negative values to numerical results in a way that tightly limits how much a single individual could influence the final output.
- Gaussian noise mechanism: Adds random variation that allows a small, controlled chance of greater deviation in exchange for more flexibility and accuracy in large or complex analyses.
- Randomized response: Limits disclosure of individual answers by requiring respondents to randomize their responses, while still enabling accurate aggregate analysis.
- Sampling and subsampling: Refers to the analysis of random subsets of data, reducing the impact of any single individual on the final results.
- Aggregate-only query system: Restricts access to data by allowing only summary statistics rather than individual-level queries, and is often combined with differential privacy noise mechanisms to enforce formal privacy guarantees.
Further reading
- What is data anonymization? Benefits, methods, and best practices
- What is data privacy and why it matters: A complete guide
- How to hide your IP address and protect your online privacy


