
Expressvpn Glossary
Data redundancy

What is data redundancy?
Data redundancy is the practice of storing the same data in multiple locations, either within a single database or across different storage systems. This practice ensures data availability and helps to prevent data loss in the event of a system failure, hardware malfunction, or cyberattack.
Types of data redundancy
Organizations use several redundancy methods depending on how quickly they need data to be recoverable and how much risk they’re willing to tolerate.
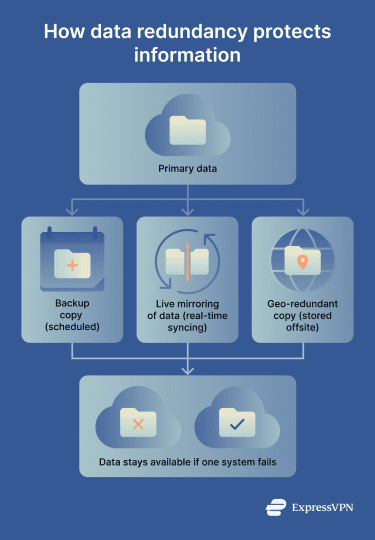
- Backup redundancy: The simplest form of redundancy, where copies of data are created and stored separately from the original. Network backups can be scheduled at regular intervals and kept on external drives, tape storage, or cloud platforms.
- Mirroring: A real-time storage replication method where data is written to two or more storage devices simultaneously. If the primary drive fails, the mirrored copy is immediately available with no recovery delay.
- Redundant Array of Independent Disk (RAID) systems: RAID combines multiple physical drives into a single logical unit. Different RAID levels offer varying balances between redundancy, performance, and storage efficiency. Some prioritize speed, while others emphasize fault tolerance.
- Geographic redundancy: Also called geo-redundancy, this involves replicating data across physically separate locations in different regions. This protects against natural disasters, localized cyber incidents, power failures, or network outages.
Advantages of data redundancy
Maintaining redundant copies of data helps organizations improve resilience across their systems and services:
- Business continuity: If a storage device fails, redundant copies ensure data stays accessible without interruption, minimizing downtime and disruption.
- Geographic resilience: Geo-redundancy keeps services running even if entire data centers go offline due to natural disasters, power outages, or other infrastructure failures.
- Improved data integrity: Keeping multiple copies enables cross-verification; each copy can be compared with others to detect corruption or inconsistencies. This protects against data loss caused by hardware failures, software bugs, or malicious activity.
- Regulatory compliance: Many industries, such as healthcare and finance, have legal requirements to maintain reliable backups of sensitive data, and redundancy helps meet these standards.
Security risks and considerations
While data redundancy strengthens resilience, it also introduces security challenges. For example, keeping more copies of data increases the number of locations that need protection. Each redundant copy is also a potential target for unauthorized access, expanding the attack surface; if backups are mismanaged and stored without proper access controls, they can become vulnerable entry points for attackers.
Additionally, when updates or deletions aren't properly synchronized across all copies, inconsistencies can arise that compromise data quality. Proper maintenance and testing are essential to avoid these problems and ensure the copies are working and ready for use in the event of an emergency. Maintenance also prevents unnecessary duplication, which can cause extra expenses.
Most importantly, backup systems require the same strong encryption and permissions as primary systems. Security and data privacy measures must extend to all copies to prevent redundant data from becoming a liability rather than an asset.
Common use cases
Intentional data redundancy is used in many personal and business contexts. Cloud storage providers, for example, use data duplication for both individual and enterprise customers to minimize the chances of data loss.
Businesses also maintain redundant data to recover from disasters as quickly as possible, and critical industries such as healthcare rely on redundancy strategies to maintain uninterrupted access to essential systems.
Redundancy tactics are also important for the smooth operation of high-availability services. Applications use redundant database clusters to ensure continuous service, even when individual servers fail.
Further reading
- Internet infrastructure: What it is and how it works
- What is a data warehouse? Secure your business insights
- What is data privacy and why it matters: A complete guide


