Department stores and online retailers exposed in AI chatbot logs and audio recordings data leak

I recently discovered 3 separate publicly exposed databases that were not password-protected nor encrypted. The databases contained a total of 3.7 million chat log transcripts, audio recordings, and text transcriptions of phone calls ranging from 2024-2026.
In a limited sample of the exposed documents I reviewed as part of the investigation, all of the files contained references to Sears Home Services. The transcripts and audio files were in English and Spanish and referenced “Samantha” and “KAIros.”
The files also contained personally identifiable information (PII) of customers, including names, physical addresses, email addresses, and some contained phone numbers, as well as details about products, accounts, services, repairs, or delivery appointments. In one CSV file, I saw 54,359 complete chat logs from start to finish.
I immediately sent a responsible disclosure notice to Sears Home Services’ parent company, Transformco; the database was restricted from public access the following day and no longer accessible.
I received a reply stating they had forwarded my notice to the person who manages the Samantha AI chatbot. However, I did not receive a reply from that individual, nor did anyone respond to a second follow-up message.
Although the records belonged to Sears Home Services, it is not known whether the database was owned and managed directly by them or by a third-party contractor. It is also not known how long the database was exposed before I discovered it or whether anyone else may have gained access to it. Only an internal forensic audit could identify additional access or potentially suspicious activity.
Sears Home Services is a Chicago, Illinois-based retail and repair business that was originally founded in 1892. According to their website, Sears Home Services is the leading appliance repair service in the United States.
Overview of the exposed databases
- Scheduling transcripts from AI chat: 2,116,011 TXT files that contained names, phone numbers, physical addresses, and user-submitted PII.
- Scheduling logs: 207,381 XLSX files and audio recordings totaling 415.2GB
- Audio scheduling calls: 1,442,577 audio recordings of customers and their text transcripts totaling 3.9TB
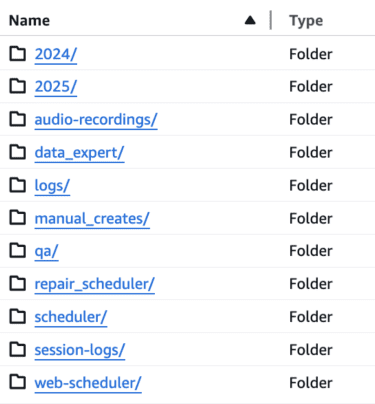 This screenshot shows how the folders appeared in one of the publicly exposed databases.
This screenshot shows how the folders appeared in one of the publicly exposed databases.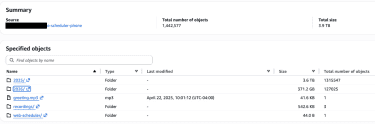
This screenshot shows an index of audio recordings with 3.9TB of biometric voice data.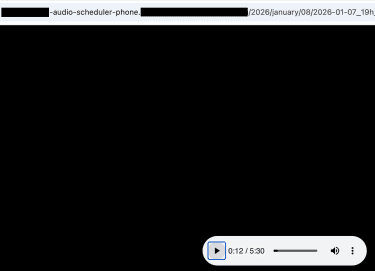
This screenshot shows how audio files could be played in any web browser
This screenshot shows how the text transcripts appeared in the database that captured customer interactions.
This screenshot shows how email addresses appeared in the chat transcripts.
This screenshot shows a transcript of how calls continued recording and logging audio to text for up to 4 hours.
According to an interview from the 2023 AI Summit in NYC with the head of AI technology at Sears, it was stated that “Sears is focused on building an organization of bots.” KAIros was developed by Sears and described as an ecosystem that includes a service scheduler for appointments, Fix Genius for diagnosing and repairing appliances, and HireHub, an HR tool for recruitment, from sourcing candidates to onboarding. While the scheduling logs indicated KAIros, I did not see any HR- or Fix-related files in the publicly accessible databases.
AI-assisted agents can be beneficial in customer interactions by improving response times, providing consistent support, and helping human agents handle complex or high-volume requests. However, when these interactions are recorded and logged, especially if they include customer PII, biometric voice recordings, or other sensitive information, they can introduce a range of potential privacy risks if the data is improperly secured or publicly exposed.
In this case, the publicly accessible AI chatbot and virtual assistant logs captured information in plaintext, including direct identifiers such as phone numbers, customer names, physical addresses, email addresses, and details about products and appointments. The combination of such a wide range of data points could potentially provide enough information for identity linking or social engineering attempts using insider information that only the service provider and the customer should know.
Additionally, metadata with timestamps, unique IDs, hashcodes, and internal events could potentially help correlate sessions across systems, reconstruct user behavior patterns, or link transcripts to other datasets. I saw text transcripts that contained links to the audio recordings they were created from, revealing the additional databases. Even if internal IDs aren’t directly exploitable, they could hypothetically become pivot points for misuse.
Audio recordings of customer phone calls communicating with an AI chatbot, voice assistant, or human agent introduce a wide range of potential security and privacy risks. Voice data is considered a biometric fingerprint and can be far richer than text alone. Voice recordings are biometric data because they capture unique characteristics that can be used to identify or verify a specific individual. According to research, criminals can clone voice audio using as little as 30 seconds of audio. It is estimated that deepfake‑enabled fraud losses are forecast to reach US $40 billion by 2027.
Unlike structured databases of text documents, audio files may contain unwanted recordings. I heard numerous calls where customers called and didn’t hang up, and the chatbot continued to record up to 4 hours of audio, including conversations unrelated to the products or services, raising additional potential privacy concerns. I am not saying users were ever at risk of voice cloning or other fraudulent activities; I am only highlighting real-world hypothetical scenarios of how criminals are using audio data and generative AI.
Exposing full chatbot logs and internal functionality can potentially reveal system prompts, conversation flows, guardrails, tuning decisions, and the accumulated knowledge that took significant resources to develop. Hypothetically, a competitor could reverse-engineer the assistant, replicate its behavior, shortcut years of research and development, and launch a similar product at a fraction of the cost.
From a security and abuse standpoint, malicious actors could use the exposed logic to identify weaknesses, bypass safeguards, and weaponize the assistant at scale. Knowing exactly how the bot decides, escalates, refuses, or complies makes it far easier to manipulate it for fraud, misinformation, or automated social engineering.
My advice to anyone that may have had their PII exposed in a data breach is to be aware of common tactics that criminals use. Knowing the basics of how to identify and prevent phishing attempts, identity fraud, or account takeovers can help protect user data and privacy.
I recommend being cautious when receiving unsolicited emails, texts, or phone calls that reference information you may have previously shared with a company or service. Criminals often request additional personal data such as tax IDs or financial details. It is a good idea to verify suspicious requests and only communicate with an organization directly through official websites, emails, or phone numbers. It is best to treat any unexpected request for personal information as suspicious until it has been independently verified. In the age of voice cloning, even friends and family should have a codeword that identifies and confirms it is really them asking for help or money.
I imply no wrongdoing by Sears, Transformco, or any contractors, affiliates, or related entities. I do not claim that internal, customer, or user data was ever at imminent risk. The hypothetical data-risk scenarios I have presented in this report are strictly and exclusively for educational purposes and do not reflect, suggest, or imply any actual compromise of data integrity or illegal activities. This report should not be construed as an assessment of, or a commentary on, any organization’s specific practices, systems, or security measures.
As an ethical security researcher, I do not download the data I discover. I only take a limited number of screenshots when necessary and solely for verification and documentation purposes. I do not conduct any activities beyond identifying the security vulnerability and notifying the relevant parties. I disclaim any and all liability for any and all actions that may be taken as a result of this disclosure. I publish my findings to raise awareness of issues of data security and privacy. My aim is to encourage organizations to proactively safeguard sensitive information against unauthorized access.



