Expressvpn Glossary
Synthetic data

What is synthetic data?
Synthetic data is artificially generated data that mirrors the patterns and structure of real-world data. It’s used to train and test machine learning (ML) models, evaluate system behavior, test application programming interfaces (APIs), and simulate scenarios when real data is limited, restricted, or poses privacy or compliance risks.
Common use cases
Synthetic data supports a range of tasks that can benefit from artificial information. Some common examples include:
- ML training: Helps train AI and ML models when real data is scarce, expensive, or may impact user privacy and present a compliance issue.
- Software testing: Enables developers and testers to simulate realistic user behavior or system loads without exposing actual user records. Synthetic data is also useful for testing APIs.
- Data sharing: Facilitates safe exchange of data between teams or external partners by removing personal identifiers while preserving meaningful structure.
- Fraud detection and cybersecurity: Assists in training detection systems by generating examples of malicious activity that may not appear often in real data.
Types of synthetic data
- Fully synthetic: Data generated entirely by algorithms that replicate the statistical properties of a real dataset.
- Partially synthetic: Only selected attributes (e.g., sensitive or identifying fields) are replaced with artificial values, while other variables remain real.
- Hybrid: Real and synthetic records combined into a single dataset, usually accomplished by adding synthetic records to a real dataset.
Why is synthetic data important?
Synthetic data is useful for:
- Protecting personal and confidential information by eliminating direct identifiers. The data can then be safely stored, shared, or used to test systems or train models.
- Reducing regulatory risks under frameworks like the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA).
- Speeding up development in industries like AI, finance, and healthcare where access to real data may be restricted or costly.
How is synthetic data generated?
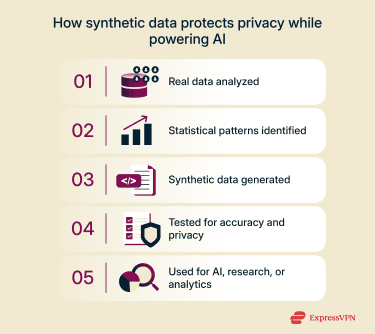 Synthetic data generation begins with the analysis of patterns, distributions, and relationships within a real dataset. Generative models like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) then produce new data points that follow the same statistical structure and any required business or system rules. The final output is then checked and adjusted to ensure it’s still useful and that identifying data has been properly minimized.
Synthetic data generation begins with the analysis of patterns, distributions, and relationships within a real dataset. Generative models like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs) then produce new data points that follow the same statistical structure and any required business or system rules. The final output is then checked and adjusted to ensure it’s still useful and that identifying data has been properly minimized.
Security and privacy considerations
Synthetic data should not be traceable back to the original records, and risk metrics such as identity, attribute, and membership disclosure can be used to assess whether any information could be exposed. Encryption of data both in transit and at rest also helps prevent tampering and unauthorized access during transfer and storage.
Advantages and limitations of synthetic data
Advantages
- Ensures the privacy of individuals isn’t put at risk by replacing personal records with artificial data.
- Allows faster access to usable data; teams can generate data tailored for testing, analytics, or development without waiting for real-world data collection.
- Reduces dependency on sensitive real-world datasets, lowering compliance burdens and allowing broader freedoms to share and experiment.
- Improves cost efficiency because collecting, labeling, and preparing real-world data is often expensive and time-consuming.
Limitations
- Poorly generated synthetic data can introduce or amplify biases, skewing ML outcomes.
- Careful validation is needed to ensure statistical accuracy and representativeness of the original data distributions.
- Struggles to capture rare events, edge cases, or long-tail patterns as effectively as real data, which can cause models to underperform on uncommon but important scenarios.
Further reading
- What is data anonymization? Benefits, methods, and best practices
- What is synthetic identity theft, and how can you prevent it?
- How data leaks are fueling the surge in identity theft cases


