

Expressvpn Glossary
Data independence

What is data independence?
Data independence is the ability of a database system to keep changes at one level from disrupting another level. In simple terms, it means data can be reorganized or redefined without forcing every application or user view to change.
This is a core principle of database design because it helps systems stay stable as they grow and change over time.
How does data independence work?
Data independence works through a layered database structure:
- External layer: What users or applications see.
- Logical layer: Defines how the data is organized.
- Physical layer: Determines how the database stores it.
Each layer has its own schema. The external schema describes user views, the logical schema defines the overall structure of the database, and the internal schema covers storage details such as files, record formats, and access paths.
The database management system (DBMS) links these layers via mappings that translate requests from one level to the next. When a change occurs at one layer, the DBMS can often accommodate it by updating the relevant mapping, so higher-level schemas and applications do not always need to change. This is easier for physical changes, such as storage or indexing changes, than for logical changes that affect the data structure applications rely on.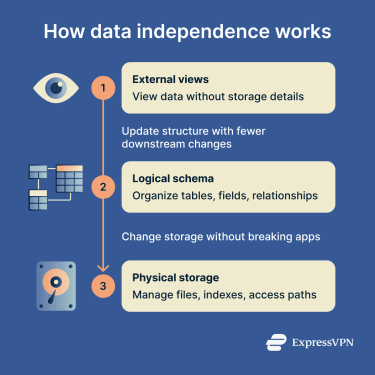
Types of data independence
There are two types of data independence: physical and logical. Each describes how the system handles changes at a specific layer without affecting other parts.
Physical data independence
Physical data independence is the ability to change how data is stored without affecting the logical schema or requiring application changes. This includes changes to storage details such as file organization, indexing, or hardware.
These changes remain invisible to users because the logical view of the data stays the same. Physical data independence is generally easier to achieve since it doesn’t alter how the system structures or interprets data.
Logical data independence
Logical data independence is the ability to change the logical structure of data without affecting user views or applications.
This includes changes such as adding fields or modifying tables. Because these changes are closer to how applications interact with data, they are harder to implement without disrupting existing functionality.
Why is data independence important?
Data independence makes databases easier to update. Teams can change storage details or adjust data structures without rewriting applications, reducing effort and speeding up maintenance.
It also reduces operational risk by limiting how far a change spreads. This helps prevent errors and disruptions during updates.
Because systems can evolve without breaking existing workflows, data independence supports scaling and keeps applications running during internal changes.
Over time, this separation improves system resilience, making it easier to maintain and adapt databases as requirements change.
Where is it used?
Data independence is used in systems that need to handle frequent updates with minimal disruption to day-to-day operations.
Common examples include enterprise databases, cloud data platforms, banking and financial systems, healthcare record systems, and other large business applications.
In these environments, teams often need to scale infrastructure, optimize storage, or adjust database design while keeping applications and user access stable.
Risks and privacy concerns
Poor data independence implementation or weak controls can introduce two main risks:
- Data exposure: Poorly defined schemas, views, or storage settings can give users or applications access to sensitive data they shouldn’t see. This risk increases in complex or distributed systems where misconfigurations are harder to detect.
- Misconfigured access controls: Structural changes, inconsistent permissions across layers, or incorrectly updated mappings can disrupt existing access rules, allowing authorized users to gain broader access than intended.
Older or tightly coupled database designs may lack clear separation between layers, making these risks more likely during updates or maintenance.
Further reading
- What is a data warehouse? A complete guide
- What is big data security and privacy?
- What is the CVE database and how does it work?
- Data sovereignty: What it is and compliance considerations
- Data scraping: What it is and how it works


