Anonymized demographic data can still be used to identify you


If you’re one of the few people who read terms of service, you may find buried in various companies’ privacy policies a clause saying that they may collect and sell your data to third parties.
The data, they say, is anonymized, but a new study published in Nature Communications demonstrates that, depending on what you share, it can still be possible to re-identify you with astonishing accuracy. Researchers from Imperial College London and the University of Louvain in Belgium created a machine-learning model that can reidentify individuals from anonymized datasets, even from “heavily incomplete datasets.”
Such revelations come at a time where more people are wary of companies selling their data to third parties, and have damning privacy implications for the currently stored (and shared) anonymous data that many companies and academic institutions collect and use.
How does data anonymization work?
Unless you’re completely off the grid, you’re regularly producing a lot of personal data—from your online purchases and your running routes to more personal data like your health records.
Such data troves are gold dust for advertisers that want to improve their targeting (read: Cambridge Analytica), and for researchers looking for trends in public health, and to teach facial recognition to artificial intelligence.
To protect the identities behind the data, the general 'best practices' have been to remove obviously identifying information like names, email addresses, and phone and social security numbers.
[Want more privacy and security news? Sign up for the ExpressVPN blog newsletter.]
Outdated anonymization techniques
Many of the popular methods of anonymization have remained unchanged since the 1990s, failing to adopt more complex anonymization techniques in response to the explosion of online data since.
There have been several instances, dating back to as early as 2000, of supposedly anonymous datasets that were released and subsequently re-identified.
In 2017, journalists successfully “re-identified politicians in an anonymized browsing history dataset of 3 million German citizens, uncovering their medical information and their sexual preferences.”
The new study also points to previous work in which researchers were able to “uniquely identify individuals in anonymized taxi trajectories in NYC, bike sharing trips in London, subway data in Riga, and mobile phone and credit card datasets.”
Few data points needed to re-identify you
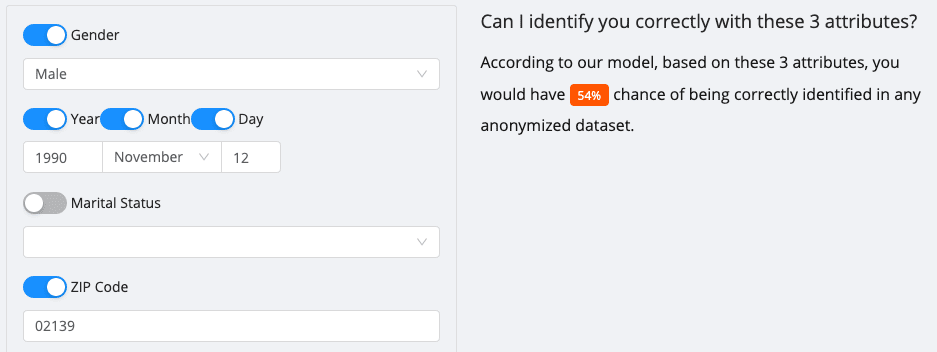
The researchers behind the study have built an online form where you can test out your chances of being identified (for U.S. and UK residents only) from a hypothetical health insurance company with just three data points: your gender, date of birth, and postcode.
For instance, if you were a U.S. male born on November 12, 1990, and currently living in the 02139 ZIP code, there’s a 54% chance your employer or neighbor could identify you.
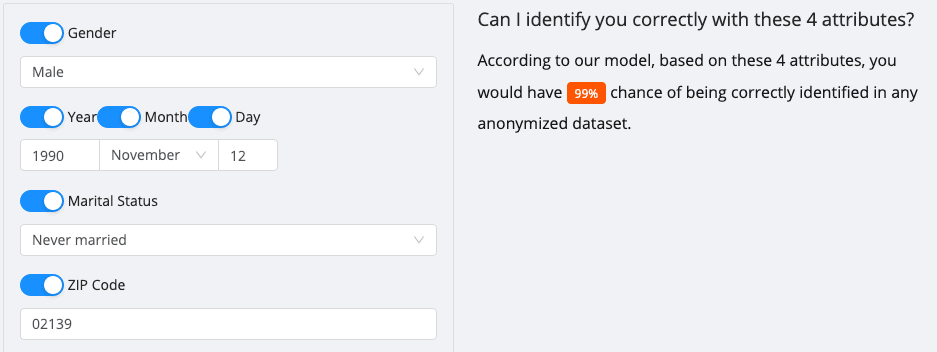
 But that percentage increases when you add more attributes: Adding your marital status alone could increase the chance of identifying you up to 99%. Other attributes include number of vehicles, workclass (chosen industry), and house ownership.
But that percentage increases when you add more attributes: Adding your marital status alone could increase the chance of identifying you up to 99%. Other attributes include number of vehicles, workclass (chosen industry), and house ownership.
How should companies be anonymizing our data?
It is clear from this study that current anonymization practices do not adequately protect people’s privacy and leave them vulnerable to being re-identified by anyone who has access to that data.
Unfortunately, there’s not much that the individual can do here—it’s up to the companies and institutions that store, sell, and use this data to change how they anonymize the data. Regulations like the EU’s GDPR and California’s Consumer Privacy Act both require the individuals in all datasets to be anonymous and impossible to be re-identified, but holding companies accountable may prove difficult.
One way to prevent re-identification in anonymized data is to adopt differential privacy, a mathematical model that carefully adds a controlled amount of random “noise” into the data before it’s sent to a server, making the data a little more approximate than accurate, but adequately protects the individual’s privacy. Companies like Apple and Google have incorporated differential privacy into their data collection.
We’ll see differential privacy put to the test in a big way soon: it will be used in the next U.S. census.
Steps you can take to protect yourself
So when a company asks your permission to share anonymized data with third parties, what should you do? Consider anonymizing your data yourself. Not every company is really entitled to your true birthdate, your actual postal code, your gender or marital status, or even necessarily your real name. If a detail is not crucial to your use of a particular service, sprinkle some inconsistency around. (And if a uniquely misspelled name starts showing up in your mailbox, you’ll know exactly which company sold you out.)
Better yet, only do business with companies that are totally upfront about what data they collect, that never collect any data they don’t need, that never share or sell your personal information with any third party, and that take anonymizing of even basic diagnostic information deadly seriously (and even allow you to opt out, if you wish). We happen to know of at least one.