What is a data warehouse? A complete guide for secure data management



Data warehouses are the backbone of modern analytics. They store large amounts of structured data from various sources, allowing organizations to analyze information, identify trends, and make data-driven decisions. As the foundation of business intelligence, a data warehouse also supports reporting, forecasting, and long-term planning.
This guide covers what a data warehouse is, how it differs from a traditional database, its main components, and how it helps manage data securely and efficiently.
What is a data warehouse?
A data warehouse is a centralized system designed to collect, organize, and analyze data from various sources. It allows businesses to combine information from customer relationship management (CRM) systems, enterprise resource planning (ERP) software, and marketing platforms into a single repository. This consolidation ensures consistency, reduces redundancy, and enables accurate reporting.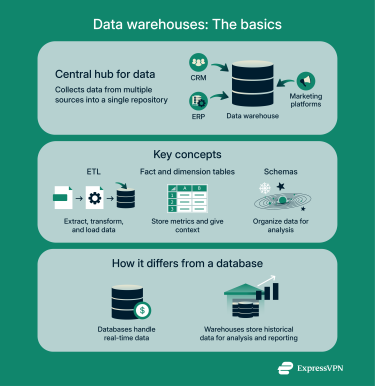
Data warehouses differ from traditional databases in several key ways. A traditional database handles real-time transactions for specific applications like accounting or inventory. It focuses on speed and efficiency for daily operations. A data warehouse, on the other hand, combines data from multiple sources and stores historical information for analysis. It’s built for large-scale queries, trend discovery, and strategic decision-making rather than routine processing.
Common use cases and business applications
Data warehouses support a variety of business needs, from combining information across departments to improving customer experience and meeting regulatory requirements. They act as a central hub, making it easier for organizations to analyze data, spot trends, and make informed decisions.
Centralizing data from multiple sources
One common application is centralizing data from multiple sources. By combining information from sales, marketing, and finance systems, organizations can create a unified view of their operations. This consolidation reduces inconsistencies and ensures that decision-makers are working with accurate data.
Customer profiles and personalization
Another important use case is creating detailed customer profiles for personalization. With historical purchase data, engagement metrics, and behavioral patterns, businesses can tailor marketing campaigns, recommend products, and segment audiences effectively.
This kind of insight is important for improving customer experience and driving loyalty. At the same time, collecting and analyzing such detailed data can have negative implications for user privacy, as it may involve tracking sensitive behaviors and creating profiles that users might not be fully aware of or have consented to.
Regulatory reporting and compliance
Data warehouses play a vital role in regulatory reporting, compliance, and protecting data sovereignty. By maintaining accurate and auditable records, organizations can demonstrate their compliance with data processing and retention requirements under regulations like the General Data Protection Regulation (GDPR), the Health Insurance Portability and Accountability Act (HIPAA), and applicable financial reporting standards. Automated reporting reduces the risk of errors and ensures that critical information is always available when needed.
AI training
Data warehouses enable AI-driven insights by providing a structured environment for model training. For example, an e-commerce company can use its warehouse to feed machine learning models with customer purchase histories and browsing patterns. These models analyze past behavior to forecast future buying trends and deliver personalized product recommendations tailored to each customer.
Data warehouse vs. other storage systems
Understanding the differences between a data warehouse, database, and data lake is essential for choosing the right solution for your organization’s needs. Each system serves a distinct purpose and has unique strengths.
Data warehouse vs. database
Databases handle everyday operations, whereas data warehouses are built for analysis and reporting. The table below highlights the key differences.
| Feature | Database | Data warehouse |
| Purpose | Designed for real-time transactional processing, such as recording sales, updating inventory, or managing customer interactions | Focuses on analysis and reporting, consolidating historical data from multiple sources |
| Strength | Handles large numbers of small, concurrent transactions quickly | Supports complex queries, data aggregation, and long-term trend analysis |
| Data type | Current operational data | Summarized data and historical data |
| Users | Database administrators, architects, and data analysts | Business intelligence analysts and data warehouse engineers |
| Processing | Online transactional processing (OLTP) | Online analytical processing (OLAP) |
| Query type | Simple, fast transaction queries | Complex analytical and trend-based queries |
| Integration sources | Can be tied to a single application or system, or shared between multiple ones | Integrates data from multiple databases and external sources |
Data warehouse vs. data lake
Data lakes handle raw and varied data for exploration and machine learning, while data warehouses focus on structured data for fast, reliable analysis.
| Feature | Data lake | Data warehouse |
| Data type | Stores raw structured, semi-structured, or unstructured data | Generally stores processed, structured, cleaned, and organized data |
| Purpose | Flexible storage for exploratory analytics, machine learning, and big data experimentation | Optimized for fast reporting, business intelligence, and trend analysis |
| Strength | Handles massive volumes and varied formats efficiently | Provides speed, consistency, and reliability for data analysis |
| Users | Data scientists and data engineers | Business analysts, stakeholders, and decision-makers |
| Data sources | Multiple internal and external sources | Core business systems and integrated enterprise data |
| Processing | Extract, load, transform (ELT) | Extract, transform, load (ETL), though some cloud-based warehouses use ELT |
| Scalability and cost | Highly scalable and cost-effective due to flexible storage | More expensive and complex to scale (if on-premise) |
When to use each
Choosing the right system often isn’t about picking just one. Many organizations use a combination of databases, data warehouses, and data lakes, depending on the task. The right mix depends on your goals, data types, and analytical needs.
- Databases: Best for real-time operations and transaction-heavy systems. They support daily business activities such as processing sales, updating inventory, or managing customer information.
- Data warehouses: Excel in analytics, historical reporting, and business intelligence. They consolidate data from multiple sources to support trend analysis, predictive insights, and long-term strategic decision-making.
- Data lakes: Designed for large-scale, exploratory analytics. They can store unstructured and semi-structured data, making them ideal for exploratory analytics, machine learning, and big data experimentation.
Data warehouse architecture
Data warehouse architecture defines how data is collected, processed, stored, and accessed. A well-structured architecture ensures efficiency, scalability, and security while supporting analytics and reporting across an organization.
Three-tier structure explained
Most data warehouses follow a three-tier architecture, which separates data storage, processing, and access into distinct layers. This structure improves performance, simplifies maintenance, and allows analysts to access data without affecting the underlying systems.
Bottom tier: Data collection and storage
The bottom tier is where data collection and initial storage take place. It typically consists of a relational database system (RDB) or a cloud-based storage platform that serves as the foundation for the entire data warehouse.
At this stage, data is gathered from multiple sources such as operational databases that store day-to-day transactions, CRM systems that track customer interactions, flat files like CSVs or spreadsheets, and external APIs that pull information from third-party platforms. It’s then loaded into staging areas for processing.
The ETL process begins here, ensuring that the incoming data is cleaned and standardized before moving up the architecture.
This tier focuses on maintaining data integrity and consistency, since any issues at this level can affect the rest of the warehouse. Organizations often use data validation rules and automated quality checks to detect anomalies early. In secure environments, data encryption, masking, and access controls are also applied at this stage to protect sensitive information during ingestion.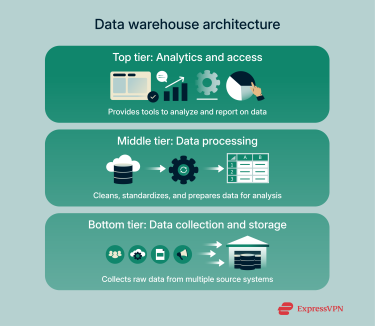
Middle tier: Data processing
This tier includes an OLAP server, which enables fast query responses and complex analytical computations. Depending on the system’s architecture, it can use one of three OLAP models:
- Relational OLAP (ROLAP): Works directly with relational databases, suitable for large datasets.
- Multidimensional OLAP (MOLAP): Uses a cube-based structure for faster calculations and summaries.
- Hybrid OLAP (HOLAP): Combines the strengths of both models, balancing scalability and speed.
Top tier: Analytics and access
The top tier provides end users with tools to analyze, visualize, and report on the data. Dashboards, business intelligence platforms, and visualization software allow teams to generate insights without interacting directly with the underlying data. This separation ensures performance remains high even as query complexity increases.
Core components
Data warehouses rely on several key components to store, manage, and deliver data effectively. Each part, from moving and transforming data to providing secure access, works together to make data useful, reliable, and easy to analyze for business decisions.
ETL/ELT tools
Extract, transform, load (ETL) and extract, load, transform (ELT) tools move data from multiple sources into a data warehouse. Traditionally, data warehouses use ETL for legacy systems, transforming data before loading to maintain structure and consistency.
That said, modern cloud-based warehouses with stronger processing power often adopt ELT, loading data first and transforming it later for better scalability and speed.
Both methods can work together in complex analytics that involve diverse data formats. Data scientists may use ETL pipelines for certain sources and ELT for others, improving overall analytics efficiency and application performance.
API layer
The API layer allows other applications to communicate with the data warehouse. It acts like a bridge, letting software, dashboards, or analytics tools request specific data without exposing the full warehouse. This ensures users and programs get the right data efficiently and securely.
Data layer
The data layer is where all warehouse data is stored. It primarily holds structured information, often organized in tables for fast and consistent access. That said, in some modern warehouses, limited unstructured or semi-structured data (such as XML files and webpages) may also be stored after being partially structured for analysis. This approach helps integrate diverse data types without turning the warehouse into a full data lake.
Overall, this layer serves as the foundation, ensuring data remains reliable, organized, and ready for analytical use.
Metadata
Metadata is essentially data about your data. It tells you where the data came from, when it was updated, and how it should be used. Metadata helps analysts understand the context of the data, improves searchability, and ensures accurate reporting.
Sandbox
A sandbox is a safe space to experiment with data. Analysts can test queries, build models, or try out new ideas without affecting the main warehouse. It’s useful for learning, prototyping, and validating assumptions before applying changes to real datasets.
Access tools
Access tools are what employees use to interact with the data warehouse. This includes dashboards, reporting software, or query interfaces. They allow users to visualize data, generate reports, and make decisions, all without needing deep technical knowledge.
Cloud-based vs. on-premise architectures
To help compare the two deployment options, the table below highlights the key features, benefits, and limitations of cloud-based and on-premises data warehouses.
| Aspect | Cloud-based data warehouse | On-premises data warehouse |
| Scalability | Easily adjust storage and computing power to handle growing or fluctuating demands | Scaling requires additional hardware and careful planning, making rapid expansion difficult |
| Management | Automatic maintenance reduces hands-on upkeep, simplifying management | IT teams must handle updates, troubleshooting, and ongoing maintenance |
| User accessibility | Intuitive design, accessible to users of all skill levels for analysis | May require more technical expertise to query and manage data |
| Security | Virtual private cloud setups and VPNs protect data and ensure compliance | Strong control over physical and network security; can be customized to internal policies |
| Cost | Pay-as-you-go pricing ensures you only pay for what you use | High upfront capital costs for servers, storage, and networking equipment |
| Data handling | Supports both structured and semi-structured data for versatile analytics | Typically optimized for structured data; handling semi-structured or modern formats may require additional setup |
| Latency | Dependent on internet connectivity and cloud provider infrastructure | Local servers provide low-latency access for fast queries |
| Data sovereignty | Data stored off-premises may raise compliance concerns in some regions | Full control over where and how data is stored, simplifying compliance with regulations |
| Maintenance and capacity planning | Largely managed by the provider; minimal IT overhead | Requires dedicated IT resources and careful planning for future capacity needs |
| Limitations | Costs can rise unexpectedly if storage or compute usage isn’t optimized, especially with large or continuous workloads | Less flexible and slower to scale; requires significant maintenance and resource planning |
Tip: Organizations using cloud data warehouse services can follow zero-trust cloud principles to strengthen protection across their storage systems.
Data modeling fundamentals
Data modeling is a critical step in designing a data warehouse. It organizes information in a way that makes querying, reporting, and analysis efficient and reliable. Proper modeling ensures data is consistent, easily accessible, and ready for business intelligence and analytics tasks.
Dimensional modeling
Dimensional modeling is a design technique that structures data into facts and dimensions. Its main goal is to make analytics intuitive and fast by organizing data around measurable events and the context that describes them. This approach simplifies complex queries and enhances reporting for business users and analysts.
Fact and dimension tables
Fact tables store quantitative, measurable data, such as sales amounts, order quantities, or revenue. Dimension tables, on the other hand, provide descriptive context, like customer information, product details, or time periods, allowing you to analyze those facts. Together, fact and dimension tables form the backbone of a warehouse’s structure.
Star, snowflake, and galaxy schemas
Schemas define how fact and dimension tables are organized and structured, which affects how easily data can be accessed and analyzed.
- Star schema: A simple layout with a central fact table connected directly to several dimension tables. This design is easy to understand and allows fast querying for common analytics.
- Snowflake schema: Expands the star schema by splitting dimension tables into smaller, related sub-tables. This reduces duplicate data, improves organization, and ensures consistency, though queries can be slightly more complex.
- Galaxy schema: Includes multiple fact tables that share some dimensions, enabling analysis across different areas of the business. This design supports complex reporting and large-scale analytics.
These schema types help organizations balance simplicity, efficiency, and analytical power, depending on their reporting needs.
Types of data warehouses
There are several types of data warehouses, each serving different purposes. Below are some of the most common models.
Enterprise data warehouse (EDW)
An EDW serves as the central repository for an organization’s entire dataset, supporting large-scale strategic decision-making and long-term analytics. Acting as the main database for the company, it consolidates information from multiple departments and systems into a single source. This ensures executives and analysts work with consistent, accurate data.
EDWs provide broad access to information across all business units, offering a unified view of the organization’s operations. This helps departments align their goals, share insights, and make decisions based on the same reliable information. The warehouse also standardizes how data is stored and managed, maintaining consistency across different sources and preventing issues caused by format variations.
EDWs are optimized to handle complex queries and large-scale analyses, allowing organizations to uncover trends, measure performance, and explore long-term patterns. Their centralized design makes them essential for organization-wide reporting and strategic planning, ensuring that decision-makers can get a comprehensive and coherent view of the business.
Operational data store (ODS)
An ODS is optimized for near real-time reporting and operational decision-making. Unlike an EDW, which focuses on historical and analytical data, an ODS handles current transactional information from multiple sources.
It acts as an intermediary between live databases and the data warehouse, enabling organizations to monitor day-to-day operations, produce timely reports, and support short-term business processes without affecting transactional systems.
Data mart (DM)
A DM is a smaller, focused subset of a data warehouse, typically designed for a specific department or business unit. By concentrating only on relevant data, DMs provide faster access for teams that require targeted analytics, such as marketing, sales, or finance.
DMs improve performance by limiting the scope of data analyzed, making queries faster and more efficient. They also increase relevance, as the data is tailored specifically to the needs of the department or business unit using it.
Building and maintaining a DM is generally more cost-effective than managing a full-scale EDW, due to its limited size and scope. Management is simplified, and the reduced data volume allows teams to handle their analytics more easily.
Finally, using DMs reduces the load on the central EDW. Offloading department-specific analyses ensures that the central warehouse maintains high performance for organization-wide analytics and reporting, making DMs a practical and efficient solution for targeted insights.
Data warehousing and cybersecurity
Despite their benefits, data warehouses are prime targets for cyberattacks due to the sensitive information they store. Cybercriminals often exploit misconfigurations or weak access controls, making security a top priority. Using VPNs can secure access to cloud-based warehouses by encrypting data in transit, which is particularly important when accessing sensitive information over public or remote networks.
Compliance is another critical factor. Regulations like GDPR and HIPAA require encryption, role-based access, and audit logging. Organizations must prevent unauthorized access, especially when teams work remotely, by combining VPNs, multi-factor authentication, and strong security policies.
Common challenges in data warehousing
Implementing a data warehouse comes with challenges, including the following:
- Latency: Data latency can delay the availability of insights, though real-time ETL or streaming solutions can help.
- Complexity: Integration issues can arise when combining diverse sources with varying formats.
- Data format issues: Traditional warehouses struggle with unstructured data, which may require hybrid solutions like data lakes.
- Expense: High costs for hardware, software, and maintenance are common, especially for on-premise setups.
- Security problems: Cloud deployments can have security blind spots if permissions and access controls aren’t carefully managed.
How to build a secure data warehouse
Building a secure data warehouse requires proactive planning and layered protections. By addressing privacy, encryption, and access controls from the start, you can safeguard sensitive data throughout its journey, from ingestion and transformation to storage and analysis.
Security considerations during ETL
During ETL, sensitive data should be encrypted, masked, or anonymized to prevent unauthorized access. Implementing these protections at the transformation stage ensures that both raw and processed data remain secure.
Best tools for secure ETL pipelines
Choosing reliable ETL tools helps maintain secure and consistent data flows. Popular options include Talend, Informatica, and Apache NiFi, which provide built-in features for encryption, auditing, and error handling.
Selecting secure cloud vendors
When using cloud-based warehouses, pick vendors with strong security certifications and compliance standards. This adds an extra layer of protection and helps meet regulatory requirements for data handling.
Using VPNs to secure data pipelines
VPNs help to safeguard connections between users, offices, and cloud environments, ensuring that data remains encrypted in transit. This reduces the risk of interception and data breaches, especially for remote teams accessing a cloud-based warehouse.
FAQ: Common questions about data warehouses
Is a VPN necessary for cloud-based data warehousing?
A VPN isn’t strictly required for cloud-based data warehousing, but it can add an extra layer of security. Many cloud providers already encrypt data in transit and at rest, but a VPN can help secure connections from your network to the cloud, especially when accessing sensitive data from remote locations.
How do you secure data warehouses?
Data warehouses are secured through multiple layers of protection, including encryption, access controls, and monitoring. Administrators typically enforce strong authentication, role-based permissions, and network security measures to prevent unauthorized access. Regular audits, activity logging, and data masking for sensitive fields further reduce the risk of breaches.
What's the difference between EDW and data mart?
An enterprise data warehouse (EDW) covers the entire organization, while a data mart is a smaller, department-specific subset of that data. EDWs integrate multiple sources to provide a unified view for analytics, whereas data marts focus on specialized needs, like sales or marketing.
Can a VPN help with regulatory compliance?
A VPN can support regulatory compliance by protecting data during transmission and ensuring secure remote access. While a VPN alone doesn’t fulfill all compliance requirements, it helps organizations meet standards by minimizing exposure to interception or unauthorized access. Combining a VPN with encryption, logging, and proper access controls strengthens overall security.
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN