What is big data security and privacy?



Big data refers to datasets that are large, complex, or fast-changing enough that they are usually stored and processed across multiple systems, rather than in a single database. Big data environments often combine information from many sources and formats to support analytics, reporting, and machine learning.
Because these systems involve large volumes of information moving across platforms, organizations typically use dedicated security and privacy practices to protect data and manage how it's handled at scale. This article explains what big data security and privacy mean, how they work, common challenges, and best practices.
What is big data security?
Big data security is the practice of protecting large datasets and the infrastructure that stores and processes them. It covers the tools, policies, and safeguards that prevent unauthorized access, detect threats, and keep data accurate and available.
What big data security protects
Big data security focuses on protecting three things: confidentiality, integrity, and availability. In security contexts, this is often called the CIA triad:
- Confidentiality ensures only authorized users can access data.
- Integrity ensures data remains accurate and isn’t altered without permission.
- Availability ensures systems and data remain accessible when needed.
In practice, this means securing data and systems across the full big data environment, including:
- Data at rest: Files and databases stored in data lakes, data warehouses, and cloud storage.
- Data in transit: Data moving between applications, services, and environments.
- Data in use: Data being processed for analytics, machine learning, or reporting.
- Infrastructure: Servers, clusters, containers, and cloud services that store and process data.
- Access and identities: User accounts, roles, permissions, and application programming interface (API) keys that control access.
- Pipelines and integrations: Ingestion tools, Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) workflows, and third-party connections.
Why big data security matters
Strong big data security helps organizations manage the risks that come with storing and using large and complex datasets. Because big data environments are complex, big data security is also a form of cybersecurity risk management. It helps organizations identify which datasets are most sensitive, understand where the biggest exposures are, and prioritize controls accordingly.
Inadequate protection can lead to serious consequences, including financial, operational, and reputational impacts. According to IBM's 2025 Cost of a Data Breach Report, the global average cost of a single data breach was 4.44 million USD. In the US, costs reached 10.22 million USD.
Beyond direct costs, breaches can disrupt business operations. It may take organizations months to identify and contain an incident, which can delay projects, interrupt services, and divert resources from other priorities.
Breaches can also damage customer trust and increase scrutiny from regulators and business partners. In heavily regulated industries like healthcare and finance, serious security failures may result in legal action, penalties, or restrictions on doing business.
What is big data privacy?
Big data privacy is the set of principles and controls for protecting personal information within large datasets. It also focuses on ensuring individuals have transparency and rights over how their data is collected, used, and shared.
This applies throughout the entire data lifecycle. It includes deciding what data to collect, how long to keep it, who can use it, and when to delete it. It also means giving people visibility into what an organization holds about them and letting them access, correct, or delete it.
How privacy differs from security
Security and privacy are related but distinct. Security is mostly technical: it's about protecting systems and data from threats. Privacy is broader, covering legal, ethical, and social questions about how data should be handled.
An organization can have strong security and still violate privacy. If a company collects more personal data than it needs, uses data for purposes people didn't agree to, or shares data with third parties without proper safeguards, that's a privacy problem even if no attacker ever gets in.
Why privacy is a major concern in big data
The sheer volume and variety of data in big data environments make it easier to uncover personal details that wouldn't be visible in smaller datasets. A dataset that seems harmless on its own can expose sensitive information when combined with other sources.
Data collected years ago can remain in storage indefinitely, available for analysis using techniques that didn't exist when it was first gathered. Regulations like the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) have emerged partly in response to these concerns. They establish rules around collecting only what's necessary, limiting how data can be used, and giving individuals rights over their own information.
How big data security works
Big data security spans multiple stages, from when data enters a system to how it’s stored, processed, and accessed. Each stage uses different security controls to protect data as it moves through the environment.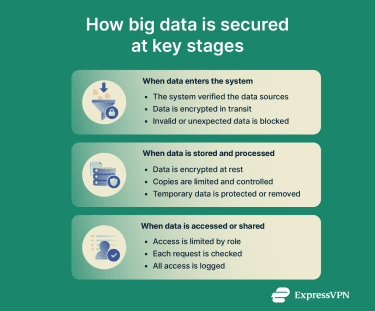
Securing data collection and ingestion
Data ingestion is the process of bringing data into the big data environment from source systems. These sources can include databases, applications, connected devices, and real-time data feeds such as social media platforms or financial markets.
Security at this stage focuses on making sure data comes from legitimate sources and hasn't been tampered with during transmission. This is made possible through several controls like:
- Transport Layer Security (TLS): Encrypts data in transit between systems to prevent unauthorized reading.
- Authentication: Verifies that data sources are legitimate and allowed to send data
- Schema validation and data checks: Flags malformed, incomplete, or unexpected data before it reaches downstream systems.
- Logging: Creates an audit trail to trace data back to its source and support investigation when needed.
Protecting data storage and processing
When data enters a system, it needs protection while it’s stored and while it’s being used. Encryption at rest turns stored data into an unreadable format that can only be unlocked with the right encryption keys. This reduces exposure if storage hardware is stolen or someone gains access to the file system.
In many big data environments, stored data is kept in cloud platforms rather than on a single on-premises server. In these cases, security also involves managing where data is stored, controlling replication and backups, and reviewing storage configurations regularly to ensure data is not unintentionally exposed.
Processing requires its own set of security controls because data may be handled in memory, cached, or written to temporary files during analysis. This involves protecting the systems that run analytics workloads, limiting who can access them, and ensuring temporary data is deleted when it’s no longer needed, or encrypted if it must be retained.
Controlling data access and sharing
Once data is stored and processed securely, the next consideration is who can access it and what they are allowed to do with it. Access control defines which users and systems can view data, modify it, or delete it. A common approach is least privilege, meaning people should only have access to the data they need for their role.
Many organizations manage access through role-based access control (RBAC). For example, an analyst may be able to query approved datasets but not change them, while an administrator may have broader permissions. More fine-grained controls can also consider context, such as the sensitivity of the data, where the request is coming from, or whether the access is happening through an approved application.
Some organizations also use zero-trust security, which treats each access request as a new decision rather than assuming users are trusted after signing in. This may include verifying identity, checking permissions for the specific request, and confirming the device meets basic security requirements. These controls help reduce the impact of compromised accounts and limit long-term access that can be misused.
When data is shared externally, additional controls come into play. Data sharing agreements define how data can be used and protected, and audit logs track who accessed what and when. This supports accountability and helps with investigation if issues arise.
Common security and privacy challenges in big data
Big data environments’ scale and complexity can make it harder to maintain consistent security controls, enforce privacy requirements, and monitor how data is accessed and used.
Loss of visibility as data scales
As data volumes grow, so does the amount of activity around that data. Every query, copy, export, and automated job creates signals that need to be monitored. At a large scale, that activity can overwhelm both tools and teams.
When monitoring doesn’t scale with data growth, risky behavior blends into normal use. Unusual access patterns may go unnoticed, and investigations become harder because there’s no clear picture of what happened and when. This makes early detection difficult and slows down response when incidents occur.
Access that accumulates and outlives its purpose
Many security incidents involve access that already exists rather than a new external intrusion. A common reason is that sometimes permissions and credentials remain active longer than intended, even after roles change or projects end.
In some cases, access spreads through reused or shared credentials, or through compromised accounts that continue to work normally. In others, access is legitimate: employees, contractors, and partners have access to systems and data that allow them to do their jobs, but it can still be misused deliberately or by accident. Because these actions can look like routine activity, misuse may not trigger alerts.
Data copied across multiple systems
Big data environments are built for reuse across teams and tools. Data is copied into analytics tools, test environments, and external services so teams can work efficiently. Over time, multiple versions of the same dataset can exist in different places.
Even if the original dataset is well protected, copied versions may not receive the same safeguards. Data can be unintentionally exposed when it is moved into an environment with weaker controls or stored with inconsistent security settings.
In some cases, copies also end up outside managed systems entirely. Teams may store datasets locally, move them into personal cloud accounts, or share them using tools that aren’t monitored by security teams. This shadow data creates blind spots, making it harder to track where data is stored and who can access it.
Compliance breakdown at scale
Privacy obligations depend on knowing where personal data is, who can access it, and how it’s used. As data spreads across systems and copies multiply, meeting those obligations becomes harder.
Common problems include keeping personal data longer than allowed, losing track of all the places it’s stored, or failing to apply access restrictions consistently. Requests to access, correct, or delete data may be fulfilled in one system but missed in others. As organizations operate across regions with different privacy laws, overlapping requirements can also add further strain.
Best practices for big data security and privacy
Strong big data security and privacy depend less on individual tools and more on how consistently controls are applied over time. The practices below focus on reducing exposure by default and limiting damage when something goes wrong.
Protect data by default, not by exception
Organizations should enable encryption by default across systems and datasets, and keep it consistently applied and updated over time.
Key management is just as important. Encryption keys should have clear ownership and controlled access, with defined processes for rotation and revocation. When keys aren’t managed carefully, encryption stops being a reliable safeguard.
Related: What are encryption protocols and how do they work?
Treat access as temporary, not permanent
Access should be treated as short-lived unless there’s a clear reason for it to persist. Permissions tied to projects or roles need explicit expiration, regular review, and clear responsibility for removal.
Identity and access management (IAM) helps enforce this by controlling who can access systems and data, and by supporting processes for updating or removing access as responsibilities change.
Automated processes and service accounts need the same discipline. These accounts often run quietly in the background and can be missed during reviews. If they’re compromised, they can provide long-lasting access that’s difficult to notice.
Plan for detection and response, not just prevention
No security control works perfectly forever, so organizations should plan for detection and response in addition to prevention. This starts with monitoring, which includes collecting and reviewing activity across systems so incidents can be identified and investigated.
In big data environments, this is done through centralized tools, like security information and event management systems (SIEM), which bring logs from different systems into one place. These tools help teams spot unusual access patterns and reconstruct what happened during an incident.
Once an incident is detected, teams need an incident response plan that defines who does what when something goes wrong. Clear ownership reduces confusion when time is tight, and testing these plans helps teams respond quickly instead of improvising.
Reduce privacy risk before security is tested
The less personal data an organization holds, the less there is to protect. Data minimization means collecting only what’s needed and keeping it only as long as there’s a clear purpose. Retention rules should be enforced in practice, not just written down.
One option is masking, which replaces sensitive values (such as names or account numbers) with placeholders while keeping the dataset usable. Another option is anonymization, which removes identifying details so individuals can’t be directly linked to the data. These techniques can be used separately or together, depending on how the data will be used.
Neither approach is perfect. In some cases, combining datasets can still make it possible to identify individuals indirectly. Even so, masking and anonymization can reduce privacy exposure when data is copied, shared, or accessed more broadly than intended.
Related: Why anonymous data isn’t as anonymous as you think
FAQ: Common questions about big data security
What is big data security and privacy?
Big data security and privacy cover how organizations protect large, distributed datasets and handle personal information responsibly. Security focuses on preventing unauthorized access, data loss, and system disruption. Privacy focuses on how personal data is collected, used, shared, and retained. Both are needed when data is spread across systems and reused at scale.
Why is privacy a concern in big data?
Big data makes it easier to reveal personal details without intending to. Information that seems harmless on its own can become sensitive when combined with other data. Large datasets also tend to persist for years, which increases the risk of misuse over time. Once personal data is widely copied or reused, it becomes much harder to control.
What are the most common risks in big data environments?
The most common risks come from loss of visibility, access that accumulates over time, and data being copied into many systems. Legitimate access can outlive its purpose, copied datasets may not receive the same protections, and activity at scale can make problems harder to detect. These conditions increase the chance of breaches, data leaks, and compliance failures.
How can organizations protect big data?
Organizations should protect data by default and limit exposure over time. That includes consistent encryption and key control, treating access as temporary, monitoring critical systems, and preparing for incidents instead of assuming they won’t happen.
Reducing how much personal data is collected and retained also lowers risk before security controls are even tested.
What regulations affect big data privacy?
Several major laws govern how personal data must be handled. The General Data Protection Regulation (GDPR) applies to the data of individuals in the EU. The California Consumer Privacy Act (CCPA) and California Privacy Rights Act (CPRA) apply to certain businesses handling data about California residents.
Other frameworks include the Health Insurance Portability and Accountability Act (HIPAA) for healthcare data and the Payment Card Industry Data Security Standard (PCI DSS) for payment data. Organizations operating across regions often need to follow more than one.
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN