Was sind IP-Adress-Klassen? Bedeutung für VPNs und Cybersicherheit



Jedes Gerät, das eine Verbindung zum Internet herstellt, benötigt eine Adresse. Damit wird es im Netzwerk identifiziert. Die Klassen von IP-Adressen (Internet Protocol) wurden eingeführt, um die entsprechenden Adressen zu organisieren. Ferner wird damit bestimmt, wie viele davon innerhalb jedes Netzwerks benutzt werden können. Das System wurde später durch ein klassenloses Modell abgelöst, das Adressblöcke effizienter zuweist.
Dennoch bestimmt die Logik der IP-Klassenstruktur weiterhin die Organisation moderner Netzwerke. Sie beeinflusst, wie virtuelle private Netzwerke (VPNs) private Adressen zuweisen, wie der Datenverkehr innerhalb von Organisationen getrennt wird und wie die Kommunikation zwischen verbundenen Systemen geschützt bleibt.
Der Artikel handelt von IP-Adressklassen. Er zeigt, wie sie funktionieren und warum das ihnen zugrunde liegende Konzept für VPNs, den Datenschutz und modernes Netzwerkdesign weiterhin wichtig ist.
Was ist eine IP-Adresse?
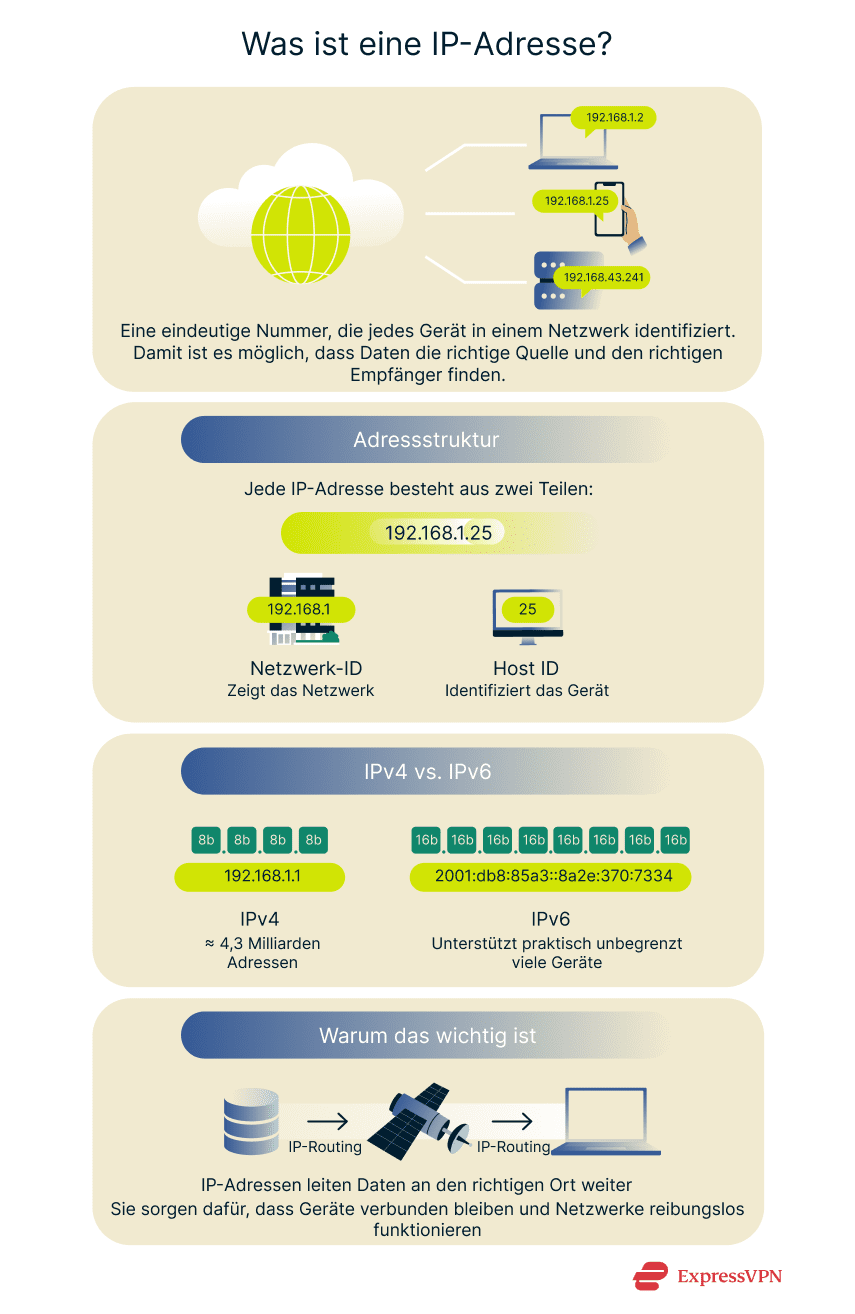 Eine IP-Adresse ist eine eindeutige Nummer. Sie wird jedem Gerät zugewiesen, das eine Verbindung zum Internet oder zu einem privaten Netzwerk herstellt, das das Internetprotokoll nutzt. Die Nummer identifiziert die Quelle und das Ziel von Datenpaketen. Damit können Systeme Daten über ein Netzwerk oder das Internet austauschen.
Eine IP-Adresse ist eine eindeutige Nummer. Sie wird jedem Gerät zugewiesen, das eine Verbindung zum Internet oder zu einem privaten Netzwerk herstellt, das das Internetprotokoll nutzt. Die Nummer identifiziert die Quelle und das Ziel von Datenpaketen. Damit können Systeme Daten über ein Netzwerk oder das Internet austauschen.
Derzeit gibt es zwei Versionen des Internetprotokolls: IPv4 und IPv6. IPv4-Adressen basieren auf dem Binärsystem und umfassen insgesamt 32 Bit. Sie sind in vier Abschnitte unterteilt, die als Oktette bezeichnet werden. Sie enthalten jeweils 8 Bit. In einer für Menschen lesbaren Form werden diese Oktette als durch Punkte getrennte Dezimalzahlen geschrieben. Das ist ein Format, das als Punkt-Dezimal-Notation bekannt ist.
Jedes Oktett kann einen Wert zwischen 0 und 255 annehmen. 8 Bit können 256 verschiedene Kombinationen darstellen (2⁸ = 256). Eine Beispiel-IPv4-Adresse sieht wie folgt aus:
192.168.43.241
Hinter den Kulissen verarbeiten Computer solche Zahlen in binärer Form. Die oben genannte Adresse würde wie folgt aussehen:
- 192 → 11000000
- 168 → 10101000
- 43 → 00101011
- 241 → 11110001
In Binärform wird 192.168.43.241 als 11000000.10101000.00101011.11110001 geschrieben.
Das Konzept stellt circa 4,3 Milliarden eindeutige Adressen zur Verfügung. In frühen Implementierungen wurden sie in feste Kategorien eingeteilt, sogenannte Klassen. Damit wollte man die Organisation und das Routing von Netzwerken vereinfachen.
Jede IP-Adresse besteht aus zwei Teilen: Der eine gibt das Netzwerk an, der andere identifiziert das Gerät (den Host) innerhalb dieses Netzwerks. Die Struktur gewährleistet, dass Daten an den richtigen Bestimmungsort gelangen. Zudem wird verhindert, dass doppelte Adressen zu Routing-Fehlern innerhalb oder zwischen Netzwerken führen.
IPv6 erweitert die IP-Adressgröße auf 128 Bit. Sie werden in hexadezimaler Form geschrieben und durch Doppelpunkte getrennt: zum Beispiel 2001:db8:85a3::8a2e:370:7334. Die Vergrößerung schafft eine immense Anzahl möglicher Adressen (rund 340 Undekillionen). Damit wird die weitere Expansion des Internets unterstützt.
Beide Versionen erfüllen dieselbe Aufgabe: Sie weisen jedem Gerät eine eindeutige Identität zu, damit sich Daten präzise zwischen Netzwerken übertragen lassen. Obwohl der weltweite Vorrat an IPv4-Adressen erschöpft ist, ist IPv4 heute noch immer der primäre Standard für den Großteil der Internet- und Netzwerkkommunikation. Die Verbreitung von IPv6 nimmt zu. Während der Übergangsphase werden beide Protokolle parallel genutzt.
Lesen Sie auch: Unterschied zwischen statischen und dynamischen Adressen
Die 5 Klassen von IP-Adressen
Als IPv4 anfänglich eingeführt wurde, war sein gesamter Adressraum in fünf IPv4-Adressklassen unterteilt: A, B, C, D und E. Jede Klasse legte fest, wie viele Netzwerke existieren durften und wie viele einzelne Hosts sich in jedem Netzwerk befinden konnten. Das System bot den ersten Netzwerkingenieuren eine planbare Methode zur Adressvergabe und zur Verbindung von Netzwerken unterschiedlicher Größe ohne Überschneidungen. Die Struktur wurde als klassenbasierte IP-Adressierung bekannt.
In dem klassenbasierten System wurde die 32-Bit-Struktur von IPv4 in feste Abschnitte für das Netzwerk und den Host unterteilt. Netzwerke der Klasse A reservierten die ersten 8 Bits für den Netzwerkteil. Klasse B verwendete 16 und Klasse C 24. Normalerweise wird das in Präfixform (/8, /16 oder /24) oder als Standard-Subnetzmaske dargestellt. Für die Klasse A ist das etwa 255.0.0.0.
Das Konzept machte die Adressvergabe in den Anfängen des Internets planbar. Große Organisationen erhielten Klasse-A-Blöcke, mittelgroße Netzwerke Klasse-B-Blöcke und kleinere Netzwerke Klasse-C-Blöcke. Die Klassen D und E waren für spezielle Zwecke reserviert: Multicasting und experimentelle Anwendungen.
Die klassenbasierte Adressierung wird für die Zuweisung neuer IP-Blöcke nicht mehr verwendet. Dennoch hilft sie dabei, die heutige Organisation von IPv4-Netzwerken zu erklären. Moderne Systeme stützen sich bei der Zuweisung und dem Routing auf sogenanntes Classless Inter-Domain Routing (CIDR). Die ursprünglichen Klassenbereiche beeinflussen allerdings weiterhin private Adressräume. Request for Comments (RFC) 1918, das private IP-Bereiche definiert, stützt sich auf die alten Klasse-A-, B- und C-Blöcke.
| Klasse | Erste Adresse | Letzte Adresse | Standardmaske | Typischer Anwendungsfall |
| A | 0.0.0.0 | 126.255.255.255 | 255.0.0.0 (/8) | Sehr große Netzwerke (historisch) |
| B | 128.0.0.0 | 191.255.255.255 | 255.255.0.0 (/16) | Mittelgroße Netzwerke (historisch) |
| C | 192.0.0.0 | 223.255.255.255 | 255.255.255.0 (/24) | Kleine Netzwerke (historisch) |
| D | 224.0.0.0 | 239.255.255.255 | k. A. | Multicast |
| E | 240.0.0.0 | 255.255.255.254 | k. A. | Experimentell |
Klasse A
Ein IP-Adressnetzwerk der Klasse A wurde für sehr große Netzwerke geschaffen. Dazu gehören etwa Regierungsbehörden, große Telekommunikationsanbieter und frühe Betreiber von Internet-Backbones. Es erstreckt sich von 1.0.0.0 bis 126.255.255.255 und verwendet ein /8-Präfix. Das bedeutet, wie oben erklärt, dass die ersten 8 Bit das Netzwerk identifizieren. Die Standardmaske lautet 255.0.0.0.
Ein einzelnes Netzwerk der Klasse A konnte über 16 Millionen einzelne Adressen enthalten. Das eignete sich für große Systeme von Regierungen, Hochschulen und Telekommunikationsanbietern, die das frühe Internet dominierten. Heute werden solche riesigen Blöcke nicht mehr als Ganzes beibehalten. Sie werden in kleinere Subnetze unterteilt, um das Routing effizienter zu machen. Zudem wird damit die Verwaltung der Adressen vereinfacht.
Klasse B
IP-Adressnetzwerke der Klasse B waren für mittelgroße Organisationen wie Universitäten, große Unternehmen und regionale Internetanbieter gedacht. Ihr Adressbereich reicht von 128.0.0.0 bis 191.255.255.255. Dabei werden ein /16-Präfix und die Standard-Subnetzmaske 255.255.0.0 verwendet.
Jeder Block der Klasse B bietet etwa 65.000 nutzbare Adressen. Das reicht für komplexe interne Systeme aus. Dennoch lässt sich der Bereich einfach verwalten. Dank dieser Balance war die Klasse B in den Anfängen des Internets eine der am häufigsten vergebenen Kategorien.
Klasse C
IP-Adressnetzwerke der Klasse C wurden für kleinere Netzwerke wie Büros, Heimnetzwerke und Zweigstellen eingerichtet. Ihr Adressbereich erstreckt sich von 192.0.0.0 bis 223.255.255.255. Das Präfix ist /24 und die Standard-Subnetzmaske 255.255.255.0.
Jeder Block der Klasse C unterstützt bis zu 254 Geräte. Die kleineren Zuweisungen waren für lokale Umgebungen effizient. Für Heimnetzwerke und Netzwerke von kleinen Unternehmen sind sie weiterhin der Standard.
Klasse D
IP-Adressen der Klasse D sind für Multicast reserviert. Dadurch kann ein Absender denselben Datenstrom an viele Empfänger senden. Im Gegensatz dazu werden bei Unicast Daten von einem Absender an nur einen Empfänger geschickt.
Der Adressbereich reicht von 224.0.0.0 bis 239.255.255.255. Geräte, die an einer Multicast-Sitzung teilnehmen möchten, treten einer Multicast-Gruppe bei. Dann empfangen sie alle Daten, die die Quelle an diese Gruppe überträgt. Multicast wird bei Streaming, Konferenzen sowie anderen Echtzeitanwendungen eingesetzt, bei denen identische Informationen effizient an mehrere Endpunkte geschickt werden müssen.
Klasse E
IP-Adressen der Klasse E decken den Bereich von 240.0.0.0 bis 255.255.255.254 ab. Sie wurden für Forschungs- und Versuchszwecke reserviert. Die Adressen werden im öffentlichen Internet nicht weitergeleitet. Die meisten aktuellen Systeme ignorieren sie bei der üblichen Kommunikation einfach.
Es wurde in mehreren Entwürfen vorgeschlagen, die Klasse E (240.0.0.0/4) neu zu verwenden, um die Erschöpfung der IPv4-Adressen zu mildern. Allerdings reserviert die Internet Assigned Numbers Authority (IANA), die die weltweite Vergabe von IP-Adressen verwaltet, die Klasse E weiterhin für nicht standardmäßige oder experimentelle Zwecke.
Spezielle IP-Adresse-Bereiche
Nicht jede IPv4-Adresse ist für die öffentliche Nutzung bestimmt. Einige sind für die interne Kommunikation, für Testzwecke oder für die automatische Konfiguration reserviert. Dank dieser speziellen Adressbereiche können Geräte auch ohne direkten Zugang zum öffentlichen Internet zuverlässig funktionieren und kommunizieren.
Reservierte IP-Adressen
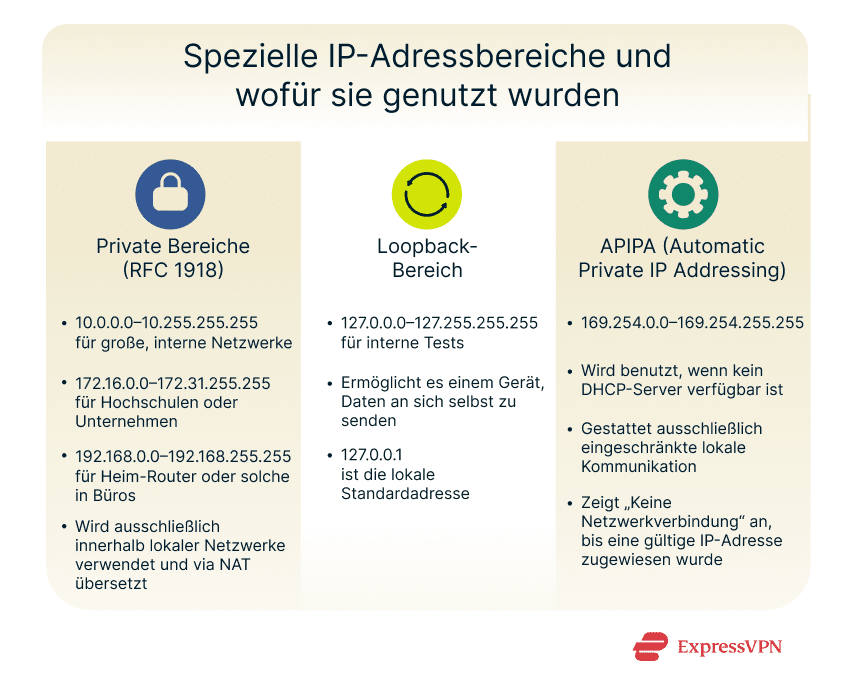
Bestimmte Adressblöcke sind für private Netzwerke reserviert und dürfen im öffentlichen Internet nicht eingesetzt werden. Sie stammen aus den traditionellen Klassen A, B und C und sind in RFC 1918 definiert.
- 10.0.0.0–10.255.255.255 (Bereich Klasse A): Dieser Block wird häufig in großen Unternehmen oder Rechenzentren eingesetzt, in denen Tausende von Geräten dasselbe interne Netzwerk nutzen. Wegen seiner Größe ermöglicht er eine flexible Unterteilung in Subnetze für verschiedene Abteilungen oder Geschäftsbereiche.
- 172.16.0.0–172.31.255.255 (Bereich Klasse B): Dieser Bereich eignet sich für mittelgroße Netzwerke. Das sind etwa Universitätsgelände oder große Unternehmen. Er bietet ein ausgewogenes Verhältnis zwischen Kapazität und Verwaltbarkeit. Der Bereich unterstützt Zehntausende von verbundenen Geräten.
- 192.168.0.0–192.168.255.255 (Bereich Klasse C): Der Adressbereich wird häufig in Routern für Privathaushalte und kleine Büros eingesetzt. Adressen wie 192.168.0.1 oder 192.168.1.1 sind gängige Standardwerte für lokale Gateways, die private Geräte mit dem Internet verbinden.
Geräte, die private IP-Adressen verwenden, sind nicht direkt über das Internet erreichbar. Müssen Sie auf externe Websites zugreifen, wandeln Router diese privaten Adressen mithilfe eines Verfahrens namens Network Address Translation (NAT) in öffentliche Adressen um.
Damit können sich viele Geräte eine einzige öffentliche IP-Adresse teilen. Dadurch wird Adressraum eingespart und die internen Adressen bleiben gleichzeitig verborgen.
Loopback-Adressen
Der Adressblock 127.0.0.0–127.255.255.255 ist für die sogenannte Loopback-Schnittstelle reserviert. Das ist eine virtuelle Netzwerkverbindung, über die ein Gerät Daten an sich selbst schickt.
Die bekannteste Adresse in diesem Bereich ist 127.0.0.1. Sie verweist einfach auf dasselbe Gerät. Alle an diese Adresse gesendeten Daten verbleiben im System und gelangen nicht über ein Netzwerk nach außen.
Die Konfiguration bietet Entwicklern und Administratoren eine sichere Möglichkeit, Software, Services und Netzwerkeinstellungen zu testen, ohne externe Verbindungen einzubeziehen. Indem Sie 127.0.0.1 öffnen lässt sich etwa ein auf Ihrem eigenen Computer laufender Webserver in einem Browser aufrufen.
Automatic Private IP Addressing (APIPA)
Kann ein Gerät keine IP-Adresse von einem Server beziehen, auf dem Dynamic Host Configuration Protocol (DHCP) (einem Netzwerksystem, das diese normalerweise zuweist) läuft, generiert es selbst eine aus dem Bereich von 169.254.0.0 bis 169.254.255.255. Das bezeichnet man als Automatic Private IP Addressing (APIPA).
APIPA ermöglicht die Kommunikation zwischen Geräten innerhalb desselben lokalen Subnetzes, wenn kein Router oder DHCP-Server verfügbar ist. Das ist etwa zwischen zwei Computern der Fall, die an denselben Switch oder denselben WLAN-Zugangspunkt angeschlossen sind. Solche Adressen sind auf den lokalen Datenverkehr beschränkt und können das Internet nicht erreichen.
Sobald ein DHCP-Server wieder verfügbar ist, gibt das Gerät seine APIPA-Adresse frei und nutzt die vom Netzwerk zugewiesene Adresse. Erhält das Gerät nach der Wiederverfügbarkeit des DHCP-Servers keine neue IP-Adresse, behält es möglicherweise seine selbst zugewiesene APIPA-Adresse bei. Gleichzeitig zeigt es möglicherweise die Fehlermeldung „keine Netzwerkverbindung" oder „kein Internetzugang" an.
IP-Adressklassen und Sicherheit bei VPNs
Die Art und Weise, wie IP-Adressen organisiert sind, spielt für ein VPN nach wie vor eine Rolle. Sie bestimmt, wie Geräte gruppiert werden und wie der Datenverkehr innerhalb des Netzwerks fließt. Zudem wird damit festgelegt, wie private Adressen vom öffentlichen Internet getrennt bleiben.
Warum VPNs auf private IP-Adressen angewiesen sind
Verbindet sich ein Gerät mit einem VPN, wird ihm eine private IP-Adresse zugewiesen, die nur innerhalb dieses Netzwerks existiert. Die Adresse stammt normalerweise aus den RFC-1918-Adressbereichen, die im öffentlichen Internet nicht geroutet werden.
Nach der Zuweisung baut das VPN einen verschlüsselten Tunnel zwischen Ihrem Gerät und seinem eigenen Server auf. Der gesamte Datenverkehr wird über diesen Tunnel geleitet. Dadurch bleiben Ihre echte IP-Adresse und die Details Ihres internen Netzwerks beim Durchqueren öffentlicher Netzwerke verborgen.
Der Server kommuniziert mit externen Websites hingegen über seine eigene öffentliche IP-Adresse. Die Trennung zwischen privaten und öffentlichen Adressen separiert die Geräte der Benutzer vom offenen Internet. Die Struktur des internen Netzwerks bleibt verborgen.
In vielen VPN-Konfigurationen von Unternehmen ist eine Segmentierung integriert. Administratoren können verschiedenen Benutzern, Abteilungen oder Remote-Standorten eigene Subnetze zuweisen. Dann können Sie für jedes davon separate Regeln für Firewalls, das Domain Name System (DNS) oder IP-Whitelisting anwenden. Dadurch wird limitiert, was jedes Segment sehen kann. Die Daten bleiben entsprechend auf die Gruppen beschränkt, die Zugriff haben sollen.
IP-Adress-Klassen und Online-Datenschutz
Websites und Online-Services können die öffentliche IP-Adresse sehen, die Ihre Verbindung nutzt. Anhand dieser Adresse lassen sich oft Ihr ungefährer Standort und der Anbieter ermitteln, der Ihren Datenverkehr abwickelt. Ein VPN ersetzt diese sichtbare IP-Adresse durch die Adresse eines eigenen Servers. Die entsprechende Website sieht also anstatt Ihrer IP-Adresse die des VPN-Servers.
Private Adressbereiche, die aus dem alten IP-Klassenmodell stammen, spielen ebenfalls eine Rolle beim Datenschutz. Geräte, die solche Adressen nutzen, befinden sich hinter Routern oder VPN-Gateways, auf denen NAT läuft. Daher sehen externe Systeme die interne Struktur nicht. Jede Anfrage scheint vom öffentlichen Endpunkt des VPNs zu stammen.
Moderne VPNs bieten zusätzlichen Schutz, indem sie ihre Server-IP-Adressen rotieren. Zudem verhindern sie DNS- oder IPv6-Lecks und blockieren alle alternativen Routen, die den tatsächlichen Standort eines Nutzers exponieren könnten. Tatsächlich fungiert das VPN als private Netzwerkschicht über dem öffentlichen Internet. Sie schützt die Identität und Daten, während der Datenverkehr durch sie läuft. Solche Schutzmaßnahmen auf Netzwerkebene entsprechen den umfassenderen Netzwerksicherheitsstandards, die in modernen Unternehmen eingesetzt werden.
Subnetzbildung (Subnetting) und ihr Zusammenhang mit den IP-Klassen
Die klassenbasierte Struktur machte die Adressvergabe zwar vorhersehbar, aber unflexibel. Benötigen Sie als Organisation etwa 500 IP-Adressen, konnten Sie keine Klasse-C-Adresse einsetzen. Damit hätten Sie nur 254 Adressen bekommen. Stattdessen mussten Sie sich für eine Klasse-B-IP mit 65.000 Adressen entscheiden. Dadurch standen Ihnen 64.500 Adressen zur Verfügung, die Sie niemals nutzen würden.
Subnetting wurde eingeführt, um diese starren Klassengrenzen flexibler zu machen. Anstatt eine gesamte Klasse A oder B als einen einzigen Block zu behandeln, können sie Adminsitratoren mithilfe von Subnetting in kleinere, logische Segmente unterteilen. Davon hat jedes einen eigenen IP-Adressbereich sowie eigene interne Routing-Regeln. Die kleineren Netzwerke, sogenannte Subnetze, lassen sich dann unabhängig voneinander routen und schützen. Das verbessert sowohl die Effizienz als auch die Kontrolle.
Was ist Subnetting?
Mithilfe von Subnetting wird ein einzelnes IP-Netzwerk in kleinere, strukturierte Teile unterteilt. Jedes Subnetz funktioniert unabhängig innerhalb des Hauptnetzwerks und ist über einen Router oder ein Gateway mit anderen Subnetzen verbunden.
Dabei werden Bits aus dem Host-Teil einer IP-Adresse genommen und zur Erweiterung des Netzwerkteils verwendet. Das legt fest, wie viele Subnetze vorhanden sind und wie viele Geräte jedes einzelne aufnehmen kann.
Angenommen, ein Unternehmen hat den Block 172.16.0.0/16. Es kann ihn in mehrere /24-Netzwerke unterteilen, von denen jedes Platz für 254 Geräte bietet. Der Adressraum vergrößert sich nicht (und schrumpft nur unwesentlich durch die Einführung einer neuen Broadcast- und Netzwerkadresse für jedes Netzwerk). Dank einer solchen Aufteilung wird das Routing vereinfacht und die Anwendung von Sicherheitsrichtlinien ist einfacher.
Subnetz vs. Subnetzmaske
Die Begriffe „Subnetz" und „Subnetzmaske" sind verwandt, haben aber verschiedene Zwecke:
- Subnetzmaske: Die Subnetzmaske ist der Mechanismus, womit die Subnetzbildung ermöglicht wird. Es ist ein 32-Bit-Muster, das den Geräten mitteilt, welcher Teil einer IP-Adresse sich auf das Netzwerk und welcher Teil sich auf den Host bezieht.
- Bits, die auf 1 gesetzt sind, markieren den Netzwerkteil.
- Bits, die auf 0 gesetzt sind, markieren den Host-Teil.
Vergleicht ein Gerät seine eigene IP-Adresse mit einer Subnetzmaske, kann es feststellen, ob eine andere Adresse zum selben Subnetz gehört oder außerhalb dieses Subnetzes geroutet werden muss.
- Subnetz: Ein Subnetz ist das Ergebnis der Subnetzmaskierung. Es handelt sich um einen kleineren, eigenständigen Teil eines größeren IP-Netzwerks. Jedes Subnetz hat einen eigenen Adressbereich, eine eigene Broadcast-Adresse und häufig auch eigene Regeln für das Routing oder den Zugriff. Es bestimmt, wo ein logisches Netzwerk endet und ein anderes beginnt.
Das gleiche Format gilt für Netzwerke unterschiedlicher Größe. Eine /24-Maske (255.255.255.0) stellt insgesamt 256 Adressen bereit. Davon sind 254 für Hosts nutzbar sind. Eine Adresse wird jeweils für das Netzwerk und für den Broadcast reserviert. Eine /25-Maske (255.255.255.128) unterteilt diesen Bereich in zwei Subnetze mit jeweils 128 Adressen. Dadurch stehen pro Subnetz 126 Hosts zur Verfügung.
Weil man Grenzen dynamisch neu definieren kann, ist das Subnetting so leistungsstark.
Zweck und Vorteile vonSubnetting
Die Subnetzbildung bietet Vorteile bezüglich der betrieblichen Effizienz und Sicherheit. Dazu gehören:
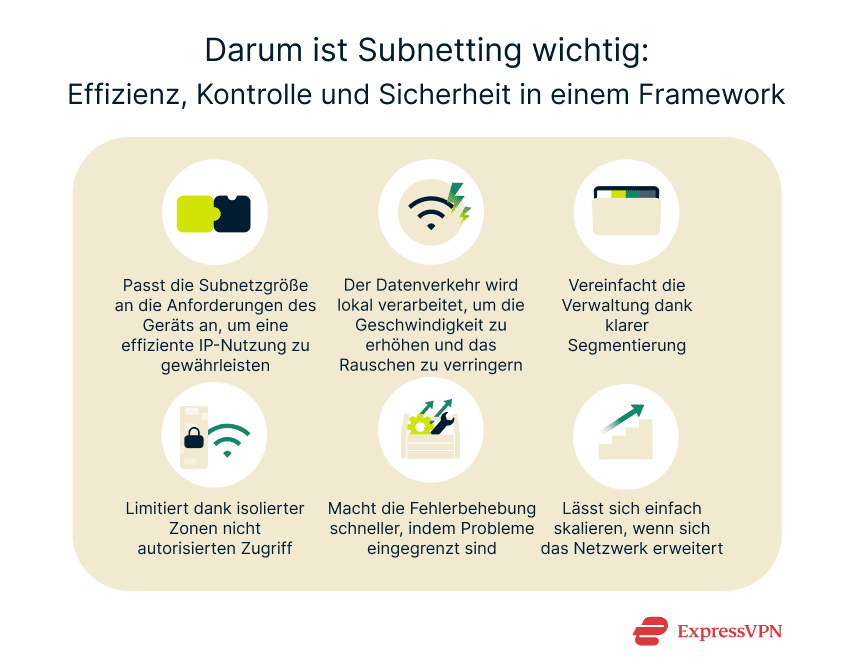
- Effiziente Nutzung von Adressen: Die Größe der Subnetze lässt sich an die Anzahl der Geräte in jedem Segment anpassen. Dadurch wird verhindert, dass große Teile des Adressraums ungenutzt bleiben.
- Leistung: Der lokale Datenverkehr bleibt innerhalb des eigenen Subnetzes. Dadurch entsteht weniger Broadcast-Verkehr und das Routing wird weniger belastet.
- Management: Die Aufteilung eines Netzwerks nach Verwendungszwecken (etwa die Trennung von Büromitarbeitern, Gäste-WLAN und Servern) erleichtert die Organisation sowie die Überwachung.
- Sicherheit: Der Datenverkehr zwischen Subnetzen lässt sich kontrollieren. Firewalls oder VPN-Gateways können verhindern, dass sich Bedrohungen über den Bereich hinaus ausbreiten, in dem sie ihren Ursprung haben.
- Fehlerbehebung: Taucht ein Problem auf, betrifft es nur das jeweilige Subnetz. Der Rest des Netzwerks läuft weiter.
- Skalierbarkeit: Wächst das Netzwerk, lassen sich später weitere Subnetze hinzufügen.
Praktische Beispiele für Subnetting
- Unternehmenssegmentierung: Ein Unternehmen, das einen 172.16.0.0/16-Block nutzt, kann ihn in mehrere /24-Subnetze unterteilen, etwa 172.16.1.0/24, 172.16.2.0/24 und so weiter. Die Firma kann jeder Abteilung einen eigenen Adressbereich sowie eigene Firewall-Richtlinien zuweisen. Ein Internetdienstanbieter (ISP) mit einem 172.16.0.0/16-Netzwerk kann seinen Kunden die Bereiche 172.16.1.0/24, 172.16.2.0/24 und ähnliche Bereiche zuweisen.
- Heimnetzwerke und Netzwerke von kleinen Unternehmen: Die meisten Router für Privatanwender nutzen standardmäßig den Adressbereich 192.168.1.0/24 und unterstützen bis zu 254 angeschlossene Geräte im Bereich von 192.168.1.2 bis 192.168.1.253. Mit einer /25-Subnetzmaske (255.255.255.128) lässt sich der Bereich in zwei kleinere Subnetze mit jeweils 126 Hosts aufteilen. Ein Bereich könnte für Arbeitsgeräte und einer für Gastverbindungen sein. Benutzer, die feste lokale Adressen für Drucker oder Server benötigen, können im Router eine statische IP-Adresse konfigurieren.
- VPN-Segmentierung: Unternehmens- und Open-Source-VPNs können verschiedenen Gruppen, Standorten oder Benutzern eigene Subnetze zuweisen. Dadurch können Administratoren für jedes Subnetz separate Firewall-Regeln festlegen. Dadurch bleibt der Datenverkehr isoliert und die Weiterleitung innerhalb des VPN-Tunnels wird vereinfacht.
Sind IP-Adress-Klassen auch heute noch relevant?
Das klassenbasierte System trug zur Organisation früherer Netzwerke bei. Allerdings wird es nicht mehr für die Adressvergabe benutzt. Es dient lediglich dem Verständnis der Struktur von IPv4. Für modernes Routing oder die Verteilung ist es jedoch nicht mehr relevant.
Nachteile des Klassensystems
Die Implementierung der klassenbasierten Adressierung war einfach, verschwendete jedoch viel Platz. Die festen Adressbereiche funktionierten, solange das Internet noch klein war. Als die Netzwerke wuchsen, stießen sie jedoch schnell an ihre Grenzen.
Große Adressblöcke wurden den frühen Netzwerken von Behörden, Hochschulen und Unternehmen zugewiesen. Kleinere Organisationen waren hingegen auf den begrenzten Klasse-C-Bereich angewiesen. Da jedes Klasse-C-Netzwerk nur etwa 250 Hosts aufnehmen konnte, gingen vielen kleinen Netzwerken die verfügbaren Adressen schnell aus.
Auch die Routing-Tabellen (die Listen, die den Routern mitteilen, wohin der Datenverkehr gesendet werden soll) wurden überlastet. Jeder einzelne Netzwerkblock musste separat erfasst werden, selbst wenn ein Großteil seines Adressraums nicht genutzt wurde.
Übergang zur klassenlosen (CIDR-)Adressierung
Um diese Einschränkungen zu beheben, wurde im Internet in den 1990er Jahren auf sogenanntes Classless Inter-Domain Routing (CIDR) umgestellt. CIDR hebt feste Klassengrenzen auf. Damit kann man Adressblöcke ausschließlich anhand der Präfixlänge definieren (etwa 192.0.2.0/23).
Das bedeutet, dass Unternehmen Adressblöcke erhalten können, deren Größe besser auf ihre Bedürfnisse angepasst ist. Internetanbieter (ISPs) können durch Routenaggregation mehrere kleinere Netzwerke zu einem einzigen Routing-Eintrag zusammenfassen.
CIDR führte zudem Flexibilität bezüglich der Vergrößerung oder Verkleinerung von Adressblöcken ein, ohne an die alten Grenzen A, B und C gebunden zu sein. Das liegt daran, dass Netzwerke dank CIDR variable Präfixlängen anstelle fester Klassengrößen verwenden können. Jeder Block konnte mit einem beliebigen Präfixwert definiert werden, etwa /22 für circa 1.000 Adressen oder /30 für nur vier. Dank dieser als Subnetting mit variabler Länge bekannte Methode können Organisationen Adressraum zuweisen, der ihren tatsächlichen Bedürfnissen entspricht. Damit werden keine ungenutzten Adressen verschwendet.
Heute wird die CIDR-Notation sowohl bei der IPv4- als auch bei der IPv6-Adressierung universell eingesetzt. Obwohl die „Klassen"-Terminologie in einigen Bildungskontexten und älteren Systemen weiterhin besteht, basieren moderne Routing- und Zuweisungsverfahren vollständig auf der Adressierung mithilfe von CIDR.
IPv6 und die Zukunft der Adressierung
CIDR verlängerte die Lebensdauer von IPv4. Wie bereits erwähnt, ging der 32-Bit-Adressraum dennoch zur Neige. IPv6 wurde entwickelt, um dieses Problem zu lösen und den Anforderungen des heutigen Internets zu entsprechen. Es verwendet 128-Bit-Adressen. Dadurch stehen genügend Kombinationen zur Verfügung, sodass ein Adressmangel kein Problem mehr ist.
Die IPv6-Adressierung basierte von Anfang an auf einem klassenlosen, hierarchischen Modell. Netzwerke lassen sich beliebig unterteilen oder kombinieren, um den Routing-Anforderungen zu entsprechen. Das gilt von globalen Anbietern bis hin zu kleinen lokalen Systemen.
Zudem bietet es Funktionen, die IPv4 nie hatte. Dazu gehören die automatische Adresskonfiguration sowie native Internet Protocol Security (IPsec). Ferner nutzt IPv6 Multicasting, um Netzwerknachrichten nur an die Geräte zu senden, die sie benötigen, anstatt sie an jedes Gerät im Netzwerk zu übertragen. Das ist schneller und reduziert unnötigen Datenverkehr. IPv4-Adressen wurden ursprünglich in 5 Kategorien unterteilt: Klasse A, B, C, D und E. Die Klassen A bis C unterstützten Netzwerke unterschiedlicher Größe. Die Klasse D wurde für Multicast eingesetzt und Klasse E war für Forschungs- und Testzwecke reserviert. Jede Klasse legte fest, wie viele Netzwerke und Hosts innerhalb ihres Bereichs existieren konnten. Private IP-Adressen sind Adressblöcke, die für den Einsatz innerhalb lokaler Netzwerke reserviert sind. Sie sind in der Request for Comments (RFC) 1918 definiert und umfassen 10.0.0.0/8, 172.16.0.0/12 sowie 192.168.0.0/16. Die Adressen sind im öffentlichen Internet nicht erreichbar. Router wandeln sie mittels Network Address Translation (NAT) in eine öffentliche IP-Adresse um, wenn Geräte eine Verbindung nach außen herstellen. Subnetting erweitert das klassenbasierte Modell. Dafür unterteilt es ein großes IP-Netzwerk in kleinere, strukturierte Segmente. Durch das Anpassen der Subnetzmaske können Administratoren steuern, wie viele Subnetze und Geräte jedes Segment unterstützt. Der flexible Ansatz verhindert die Verschwendung von Adressen. Zudem verbessert es die Netzwerkorganisation sowie die Sicherheit. Das ursprüngliche Klassensystem prägte die Organisation von IPv4-Netzwerken. Es ebnete den Weg für Subnetting, Network Address Translation (NAT) sowie die Verwendung privater Adressen. Die klassenlose Adressierung wurden inzwischen abgelöst. Dennoch hilft das Verständnis der Klassen dabei, die Logik hinter dem modernen Netzwerkdesign zu erklären. Nicht mehr länger. Moderne Netzwerke nutzen sogenanntes Classless Inter-Domain Routing (CIDR). Es weist Adressen nach Präfixlänge statt nach festen Klassen zu.
FAQ: Häufig gestellte Fragen zu IP-Adress-Klassen
Was sind die 5 Klassen an IP-Adressen?
Was sind private IP-Adressen?
Inwiefern hängt die Subnetzbildung mit den IP-Adressklassen zusammen?
Warum sind IP-Adresse-Klassen wichtig?
Werden IP-Adress-Klassen heute immer noch eingesetzt?
Machen Sie den ersten Schritt, um sich online zu schützen. Testen Sie ExpressVPN risikofrei.
Hol dir ExpressVPN